Security Systems in 2026: A Practical SOC Architecture Guide

Most security systems do not fail because the SOC bought the wrong tool. They fail because the tools never become a working system.
An alert lands in the SIEM. The endpoint console has different context. The vulnerability scanner says the asset is critical, but nobody trusts the ownership tag. Threat intel says the domain is suspicious, but the case queue has no place to use that signal. By the time an analyst understands the blast radius, the expensive security stack has turned into a tab-switching exercise.
Teams think the problem is tool coverage. The real problem is workflow architecture.
That changes the conversation. The practical question is not whether you have enough security products. It is whether your security systems move signal into decisions, decisions into response, and response back into validation without losing context at every seam.
Table of contents
- Security systems are workflow architecture, not tool inventory
- The core security systems stack in 2026
- Build around signals, not dashboards
- Detection engineering is the control plane
- Incident response needs state, ownership, and evidence
- Integrating CTEM, vulnerability, and SOC work
- What breaks when security systems are implemented badly
- Metrics that make systems operable
- Implementation sequence for resilient security systems
- Where ThreatCrush fits in the architecture
Security systems are workflow architecture, not tool inventory
A useful way to think about security systems is as production infrastructure for risk decisions. The inputs are telemetry, threat intelligence, asset context, vulnerability data, identity events, and user reports. The outputs are decisions: ignore, enrich, escalate, contain, patch, hunt, tune, or accept risk.
The mistake teams make is treating each tool as its own destination. The SIEM becomes a destination. The EDR console becomes a destination. The vulnerability platform becomes a destination. That creates activity, but not necessarily progress.
A working security system has a different shape. It has a clear boundary, shared context, explicit ownership, and feedback loops. Tools still matter, but they are components in a workflow, not the workflow itself.
Define the mission boundary
Before choosing architecture, define what the system is expected to protect and decide.
For a corporate SOC, the mission might be to detect and respond to identity compromise, endpoint intrusion, data exfiltration, exposed internet services, and abuse of privileged access. For a cloud-native company, the mission may lean harder into workload identity, CI/CD activity, secrets exposure, and cloud control plane events.
Write the boundary in operational terms:
- What assets are in scope?
- Which users, identities, tenants, and environments matter most?
- Which attack classes must be detected quickly?
- Which response actions are allowed without human approval?
- Which teams own remediation after the SOC escalates?
Practical rule: If the mission boundary is vague, every alert looks equally urgent and every tool vendor gets to define your priorities.
Map alerts to decisions
Every alert should map to a decision path. If it does not, it is not an alert yet. It is a log with ambition.
For each alert class, define:
- Initial severity and confidence
- Required enrichment fields
- Suppression or deduplication rules
- Escalation criteria
- Evidence required for containment
- Expected owner
- Closure conditions
This is where security systems become measurable. You can ask whether the system helps analysts decide faster and better. You can also see where decisions are blocked by missing context.
A detection for impossible travel is weak if it has no device posture, VPN context, user role, recent password reset, conditional access state, or business travel exception. The issue is not the alert logic alone. The issue is the decision package.
The core security systems stack in 2026
Modern security systems are usually assembled from several classes of capability. The exact products vary, but the architectural jobs are consistent.
| Layer | Primary job | What works | What fails |
|---|---|---|---|
| Sensors | Capture events and state | Endpoint, identity, cloud, network, SaaS, asset telemetry | Blind spots hidden behind dashboards |
| Controls | Prevent or contain action | EDR isolation, identity lockout, firewall block, cloud policy | Manual-only response paths for common incidents |
| Analytics | Detect patterns and correlate signals | SIEM, detection rules, behavior analytics, graph correlation | Rules without ownership or tuning history |
| Enrichment | Add operational context | Asset criticality, owner, vulnerability, threat intel, identity role | Enrichment shown in another tab instead of the case |
| Workflow | Move decisions to action | Case management, SOAR, ticketing, chat, evidence handling | Automation that fires without state or guardrails |
| Validation | Prove coverage and improve | Detection tests, purple team, attack simulation, post-incident review | Assuming deployed means effective |
The stack is not mature because it has all six layers. It is mature when the layers cooperate under pressure.
Sensors and controls
Sensors tell you what happened. Controls let you do something about it.
Common sensors include EDR telemetry, identity provider logs, DNS logs, proxy events, firewall events, cloud audit logs, Kubernetes audit data, SaaS audit trails, email security events, and vulnerability scanner outputs. Common controls include endpoint isolation, account disablement, token revocation, domain blocking, workload quarantine, firewall policy updates, and cloud permission changes.
What breaks in practice is the gap between observation and action. A system that can detect suspicious PowerShell but cannot identify the device owner, isolate the host, and preserve evidence is only partially useful.
Analytics and enrichment
Analytics convert telemetry into candidate security events. Enrichment converts candidate events into something an operator can decide on.
This is where threat intelligence, asset inventory, vulnerability context, and identity context matter. A command-and-control domain is more important if it was contacted by a domain controller. A known exploited CVE is more urgent on an internet-facing appliance than on a retired lab host. A suspicious OAuth consent event is more serious for a finance administrator than for a test account.
Related reading from our network: teams working on private communications face similar context and metadata problems in end-to-end encryption messaging architecture, where the security model is not just the message body but the operational data around it.
Case management and response
Case management is the memory of the SOC. It should hold alerts, evidence, enrichment, analyst notes, approvals, actions taken, and closure reason.
If cases live only in chat threads, the system loses institutional memory. If cases live only in tickets, analysts may lose the fast collaboration needed during active incidents. Most teams need both: structured case state plus fast communication.
For a broader operating model, the ThreatCrush guide to security operations in 2026 is a useful companion because it frames SOC architecture around people, process, and tooling rather than isolated consoles.
Build around signals, not dashboards
A dashboard is a view. A signal is a unit of operational meaning.
The mistake teams make is building security systems around screens. They ask which dashboard analysts will watch. Better teams ask which signals should enter the decision pipeline, how they will be enriched, and when they should trigger action.
Normalize events into security facts
Raw logs are messy. A cloud audit event, an EDR process event, and an identity login event may describe the same incident from different angles. Your system needs a common way to represent security facts.
A practical event contract can be simple:
event_type: suspicious_login
principal: user@example.com
asset: laptop-1842
source_ip: 203.0.113.20
time_seen: 2026-06-08T14:12:00Z
confidence: medium
severity: high
required_context:
- user_role
- device_posture
- geo_history
- recent_alerts
response_options:
- revoke_session
- require_mfa
- escalate_to_ir
This is not about creating a perfect schema. It is about preventing every integration from inventing its own language.
Keep context close to detection
Context that exists but is not attached to the alert might as well not exist during triage.
Useful enrichment includes:
- Asset owner and business unit
- Asset criticality and exposure
- User role and privilege level
- Known vulnerabilities on the affected system
- Recent detections involving the same entity
- Threat actor or campaign associations
- Prior false positive history
- Approved maintenance windows
Practical rule: Enrichment is not a lookup feature. It is part of the alert payload that determines routing, priority, and response.
When enrichment is external, analysts become human API clients. They copy an IP address, search a console, paste notes into a ticket, and repeat. That is not investigation. That is clerical load wearing a SOC badge.
Detection engineering is the control plane
Detection engineering decides what the system treats as meaningful. In practical terms, detections are the control plane for security systems.
If detection logic is ad hoc, the entire system becomes ad hoc. If detection logic is versioned, tested, mapped to risk, and measured, the SOC gets a way to improve deliberately.
Treat detections as code
A detection should have an owner, purpose, data requirements, test cases, tuning notes, expected false positives, severity rationale, and retirement criteria.
A lightweight detection record might include:
name: cloud_admin_role_assigned_to_new_identity
owner: detection-engineering
attack_stage: privilege-escalation
data_sources:
- cloud_audit_log
- identity_directory
minimum_fields:
- actor
- target_identity
- role_assigned
- source_ip
- tenant
expected_enrichment:
- actor_mfa_state
- target_identity_age
- role_sensitivity
- recent_admin_activity
actions:
- open_high_priority_case
- notify_cloud_platform_owner
- require_analyst_approval_for_containment
This turns detection from a query into an operational asset.
Validate with attack paths
Detections should not be validated only by whether the query runs. They should be validated against realistic attack paths.
Ask:
- If an attacker phishes a user, which identity events fire?
- If the attacker registers a malicious OAuth app, what sees it?
- If they move to cloud storage, which logs are reliable?
- If they disable a control, who gets notified?
- If they exfiltrate data slowly, which system correlates it?
This is why threat analysis cannot be disconnected from detection engineering. The prior ThreatCrush guide on threat analysis workflows goes deeper on connecting analysis steps so they reduce noise instead of creating more analyst work.
Related reading from our network: teams embedding secure workflows in CI/CD face similar leakage and automation tradeoffs in encrypted messaging GitHub Actions security, especially around secrets, logs, and alert handling.
Incident response needs state, ownership, and evidence
Security systems should not just detect incidents. They should preserve enough state to respond cleanly.
An incident is a sequence, not a single alert. It has scope, evidence, containment actions, business impact, communications, approvals, and post-incident lessons. If the system does not maintain state across that sequence, responders rebuild the same picture repeatedly.
Build a case lifecycle
A practical case lifecycle looks like this:
- Intake: alert, user report, threat intel hit, or hunt finding enters the queue.
- Enrichment: asset, identity, vulnerability, and threat context are attached automatically.
- Triage: analyst decides whether to close, monitor, escalate, or contain.
- Investigation: related entities, timeline, affected systems, and evidence are collected.
- Containment: approved actions are executed and recorded.
- Eradication and recovery: owner teams remediate root cause and restore normal state.
- Closure: decision, evidence, false positive status, and follow-up work are captured.
- Feedback: detections, playbooks, asset data, and controls are updated.
The practical question is whether your tools can carry a case through that lifecycle without dumping context at every handoff.
Automate handoffs without hiding judgment
Automation is useful when it reduces repeatable work. It is dangerous when it hides decisions that should be explicit.
Good automation:
- Deduplicates alerts into a case
- Adds asset and identity context
- Pulls recent related activity
- Routes by owner and severity
- Executes low-risk containment with approval
- Records actions and evidence
Bad automation:
- Closes alerts with no explanation
- Blocks indicators globally without scope
- Disables accounts without business context
- Opens tickets without owners
- Escalates everything to incident response
Practical rule: Automate evidence collection aggressively, automate containment carefully, and automate closure only when the decision criteria are unambiguous.
Integrating CTEM, vulnerability, and SOC work
Continuous threat exposure management, vulnerability management, attack surface monitoring, and SOC operations are often treated as separate programs. Attackers do not respect that org chart.
The SOC sees exploitation attempts. The exposure team sees vulnerable assets. Threat intelligence sees active campaigns. Security architecture sees compensating controls. The value appears when those signals are connected.
Prioritize exposure by exploitability
A vulnerability score alone is not enough. Prioritization should consider exploitability, exposure, asset criticality, known threat activity, available controls, and business owner.
Example prioritization model:
| Factor | Low urgency | Higher urgency |
|---|---|---|
| Exposure | Internal-only lab host | Internet-facing production system |
| Exploit status | Theoretical proof of concept | Observed exploitation or weaponized exploit |
| Asset role | Non-critical workstation | Identity, VPN, email, database, CI/CD, backup |
| Control coverage | Strong compensating controls | No EDR, weak logging, no segmentation |
| Ownership | Clear owner and patch window | Unknown owner or unmanaged asset |
That changes the conversation from patch everything faster to reduce the paths most likely to become incidents.
Close the loop after remediation
Remediation is not complete when a ticket is closed. It is complete when the security system can verify that exposure changed.
Close-loop questions:
- Did the vulnerable service disappear from the attack surface?
- Did the patch actually install on the affected hosts?
- Did the compensating control deploy correctly?
- Did detections stop firing for the same exploit attempt?
- Did the asset inventory update owner and criticality fields?
- Did the post-remediation scan confirm the fix?
Related reading from our network: the same state and verification problem appears in private media pipelines such as encrypted messaging video transcoding, where workflow integrity depends on tracking jobs, evidence, and trust boundaries across components.
What breaks when security systems are implemented badly
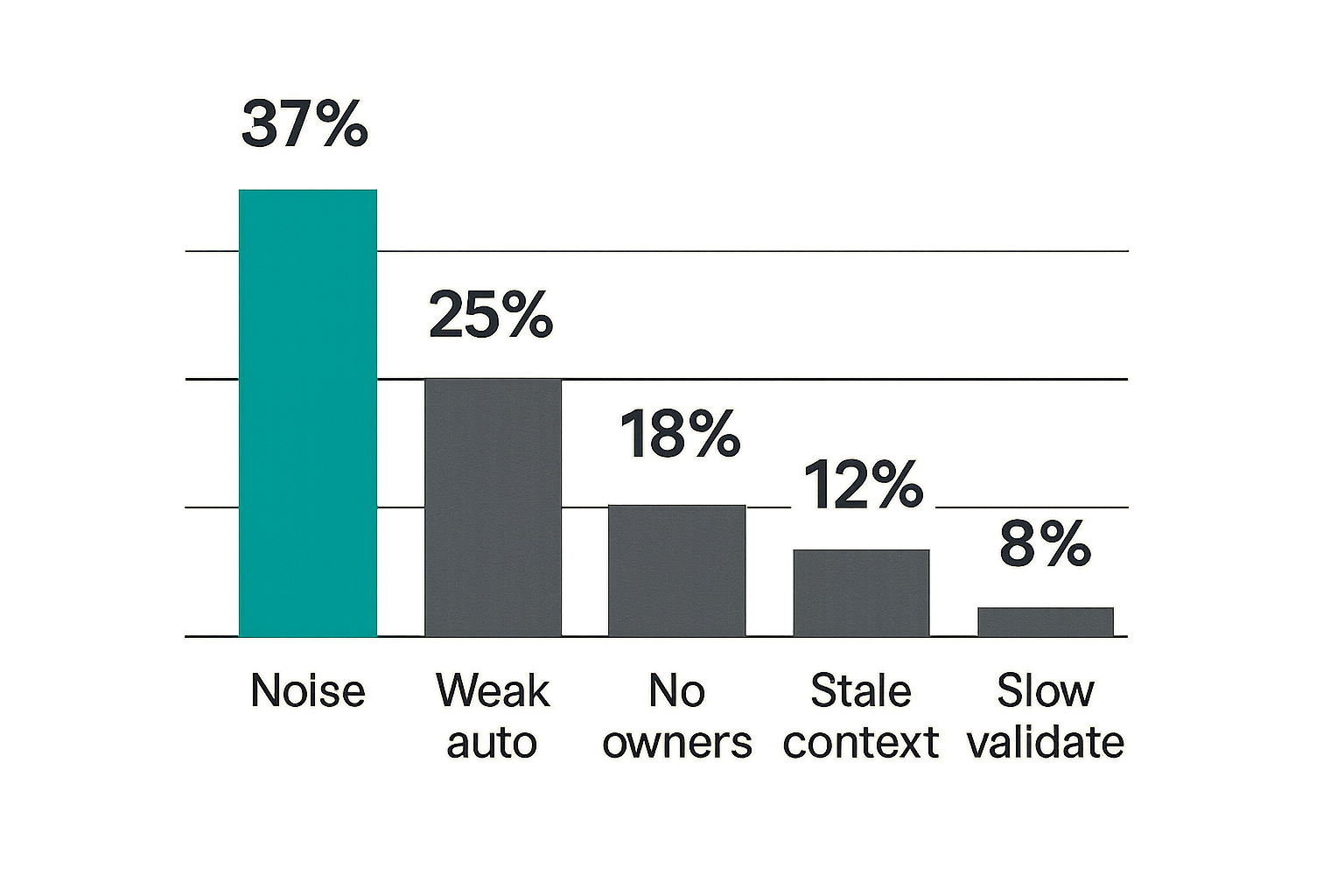
The worst security systems are not empty. They are busy. They generate alerts, open tickets, send chat messages, run automations, and fill dashboards. The problem is that the work does not reliably reduce risk.
Noise becomes work
Noise is not just an analyst annoyance. It is a capacity tax.
When low-quality alerts enter the queue, analysts still have to read them, enrich them, decide on them, and close them. Even if each one is quick, the aggregate effect is destructive. It trains analysts to expect irrelevance. It slows true positive investigation. It pushes tuning into the future because the queue is always full.
What works:
- Alert deduplication by entity and time window
- Severity based on asset and identity context
- False positive tracking by detection version
- Suppression with expiration dates
- Periodic retirement of detections that no longer carry value
What fails:
- More dashboards for the same bad alerts
- Severity copied directly from vendor defaults
- Closing alerts without tuning upstream logic
- Treating analyst exhaustion as a staffing problem only
Automation amplifies weak process
Automation does not fix unclear ownership. It accelerates it.
If the system does not know who owns an asset, an automated ticket will go to the wrong team faster. If severity is wrong, automation will escalate the wrong cases faster. If containment policy is vague, automation will create operational risk faster.
The mistake teams make is buying automation before defining safe action boundaries. Start with the decision. Then automate the evidence and routing. Then automate action where the blast radius is understood.
No one owns the seams
Many failures happen between tools:
- EDR detects malware, but the SIEM does not receive the isolation status.
- Vulnerability scanner finds a critical issue, but the SOC does not know exploit attempts are occurring.
- Threat intel flags infrastructure, but blocklists are not updated or monitored.
- Cloud alerts fire, but the platform team owns the remediation and never sees the case context.
- Identity alerts escalate, but HR ownership data is stale.
These seams need owners. Not committees. Owners.
A seam owner is responsible for the data contract, failure handling, monitoring, and periodic review of an integration path. Without that, security systems degrade silently.
Metrics that make systems operable
Metrics should help operators find bottlenecks and improve the system. They should not exist to make a dashboard look busy.
Security leadership still needs reporting, but operational metrics should answer practical questions: where are we slow, where are we noisy, where are decisions wrong, and where does context disappear?
Measure latency, not vanity
Useful latency metrics include:
- Time from event occurrence to detection
- Time from detection to case creation
- Time from case creation to first analyst decision
- Time from decision to containment
- Time from containment to remediation owner acceptance
- Time from remediation to validation
Alert volume alone is a weak metric. It can rise because coverage improved, because noise increased, or because an attacker is active. Without quality and latency context, volume is ambiguous.
A better dashboard shows the flow of work through the system and highlights stuck states.
Track quality of decisions
Decision quality is harder to measure, but it is where SOC maturity shows.
Track:
- True positive rate by detection and severity
- False positive reasons by rule version
- Reopened cases by closure reason
- Escalations accepted versus rejected by IR
- Containment actions reversed due to business impact
- Detections changed after incidents or hunts
- Cases missing required evidence fields
Practical rule: A metric that cannot change an engineering, staffing, tuning, or response decision is probably reporting decoration.
Implementation sequence for resilient security systems
Security systems improve fastest when teams implement in slices. Do not try to redesign the whole SOC in one program. Pick a high-value incident class and build the workflow end to end.
A good starting slice might be identity compromise, exposed edge appliance exploitation, ransomware precursor activity, cloud privilege escalation, or suspicious data access.
Start with services and failure modes
Choose the services that matter most, then list realistic failure modes.
For identity compromise:
- User credentials are phished.
- MFA fatigue succeeds.
- OAuth consent grants persistence.
- Session tokens are stolen.
- Privileged role is assigned.
- Mailbox rules hide attacker activity.
- Cloud storage is accessed unusually.
For each failure mode, define the telemetry, detection logic, enrichment, response action, and owner.
Connect data contracts
Then define the contracts between components. This sounds bureaucratic, but it prevents the system from becoming a pile of brittle integrations.
Minimum contract fields often include:
- Entity identifiers: user, host, IP, cloud account, workload, application
- Time fields: observed, ingested, enriched, escalated
- Severity and confidence
- Source system and rule version
- Asset owner and business unit
- Evidence links or embedded evidence
- Response actions available
- Current case state
If the SIEM, SOAR, ticketing system, and enrichment service disagree on entity identity, investigation becomes unreliable.
Roll out in slices
A practical implementation sequence:
- Select one incident class with high business relevance.
- Define the decision path from first signal to closure.
- Inventory required telemetry and identify gaps.
- Create or tune detections with explicit owners.
- Attach enrichment needed for triage.
- Build a case template with required evidence fields.
- Automate deduplication and safe evidence collection.
- Route cases to the right owner teams.
- Run tabletop and purple-team validation.
- Review metrics after real cases and tune the workflow.
This is slower than buying another console and faster than pretending the console solved the problem.
Where ThreatCrush fits in the architecture
ThreatCrush publishes for security operations professionals building and scaling SOC capabilities. The bias here is practical: connect signals, reduce noise, shorten investigations, and give operators enough context to act.
The security systems conversation is a good fit because modern SOC teams do not need more disconnected information. They need threat intelligence, vulnerability context, exposure awareness, and operational workflows that land in the same decision path.
Product fit without another swivel chair
A useful threat intelligence or exposure platform should not become one more place analysts have to check manually. It should improve the signal pipeline.
Architecturally, that means:
- Feed threat indicators into detection and enrichment paths.
- Correlate external threat activity with internal exposure.
- Help prioritize vulnerabilities that are actually relevant to active threats.
- Add actor, campaign, and infrastructure context to cases.
- Support investigation without forcing analysts to abandon their workflow.
- Provide outputs that can be validated and acted on by the SOC.
That is the standard security systems should be held to in 2026. Not more feeds for the sake of feeds. Not more dashboards for the sake of dashboards. Better decisions, faster handoffs, and cleaner validation.
Try threatcrush.com
If your security systems need better threat context, exposure awareness, and SOC-ready workflows, Try threatcrush.com. ThreatCrush is for security operations professionals building and scaling SOC capabilities.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →