Security Breach Response Architecture: A Practical SOC Workflow Guide for 2026

A security breach rarely starts with a clean incident ticket. It starts with three weak signals, an endpoint alert nobody trusts, a cloud audit event buried in logs, and a Slack thread asking whether anyone changed a firewall rule.
Teams think the problem is detecting the security breach. The real problem is operating the workflow after suspicion appears.
That changes the conversation. Detection quality matters, but so do ownership, evidence packaging, containment authority, enrichment, timelines, and decision points. A SOC can have expensive tooling and still lose hours because nobody knows which signal becomes an incident, who confirms scope, or which action is safe to take first.
The practical question is not whether your organization has an incident response plan. The practical question is whether your SOC can move from signal to decision without rebuilding the process during the breach.
Table of contents
- Security breach response is an operating system
- Define ownership before a security breach
- Build the signal architecture for security breach detection
- Triage the security breach without creating a war room bottleneck
- Investigation workflow from suspicious signal to confirmed breach
- Containment and response as controlled change
- What breaks when security breach workflows are built badly
- Metrics for reducing breach impact
- Tooling architecture for breach-ready SOCs
- Where ThreatCrush fits in a security breach program
Security breach response is an operating system
Why the first hour is usually messy
The first hour of a breach investigation is where process debt becomes visible. Analysts are not only asking what happened. They are asking where the logs live, which identity provider event matters, whether EDR isolation will break production, who owns the affected workload, and whether the legal team needs to know yet.
The mistake teams make is treating breach response as a document problem. They write a plan, store it in a wiki, and assume the process exists. In production, the real process is the route a signal takes through people, queues, tools, permissions, and decision gates.
If that route is unclear, the SOC compensates with meetings. Meetings become the workflow. That is slow, expensive, and unreliable under pressure.
Practical rule: If an analyst cannot explain the next three actions after a high-confidence breach signal, the response workflow is not operational yet.
The breach is not one event
A useful way to think about it is that a security breach is a chain of state changes. Credentials move from trusted to suspect. A host moves from managed to potentially controlled. A SaaS session moves from normal to risky. A business process moves from routine to evidence-sensitive.
The SOC has to manage those state changes without losing context. That means every meaningful transition should have an owner, a timestamp, supporting evidence, and a reversible or irreversible action attached to it.
This is why breach response architecture matters. You are not designing a heroic moment. You are designing a state machine for uncertainty.
What changes in 2026
By 2026, many environments are more distributed than their incident playbooks assume. Identity spans multiple clouds. Developers deploy through CI/CD. SaaS data is often more sensitive than endpoint data. Threat actors move through exposed services, token theft, third-party integrations, unmanaged devices, and misconfigured cloud controls.
The SOC cannot rely on one control plane. It needs a workflow that can normalize signals from endpoint, identity, network, cloud, application, vulnerability, and threat intelligence sources. If you are building broader operating models, our guide to security operations in 2026 goes deeper into the SOC architecture and maturity roadmap.
Define ownership before a security breach
Incident roles that must exist
Ownership is the cheapest breach control most teams underinvest in. Not every role needs to be a full-time job, but every role needs a named owner and backup.
At minimum, define:
- Incident commander: owns coordination and decision cadence.
- SOC lead investigator: owns evidence quality and investigation direction.
- Detection engineer: owns rule tuning, query pivots, and false-positive handling.
- Infrastructure owner: owns containment feasibility for affected systems.
- Identity owner: owns session revocation, password resets, conditional access, and privilege review.
- Communications owner: owns internal status and executive updates.
- Legal or compliance contact: owns notification obligations when required.
These roles prevent analysts from negotiating authority during the incident. They also reduce the chance that containment is delayed because the SOC is waiting for someone to approve an obvious action.
Related reading from our network: teams building local escalation systems for software delivery face similar trust and routing problems in CI/CD security community organizing.
Decision rights matter more than titles
A title does not tell an analyst what they are allowed to do. Decision rights do.
Define decision rights for common breach actions before the incident:
- Can the SOC isolate an endpoint without business owner approval?
- Can identity sessions be revoked immediately for executives?
- Can a suspicious API key be disabled if it may affect customers?
- Can a firewall rule be pushed outside the normal change window?
- Who can approve taking a production system offline?
Practical rule: For every containment action, define who can approve it, who can execute it, and what evidence threshold is required.
The evidence threshold is important. You do not want analysts waiting for perfect certainty when a token is clearly being abused. You also do not want aggressive containment based on a single low-fidelity alert. Decision rights should be tied to confidence and business impact.
Build the signal architecture for security breach detection
Map telemetry to attacker behavior
A breach-ready SOC does not collect telemetry because storage is cheap. It collects telemetry because specific attacker behaviors must be observable.
Map your signals to behaviors such as:
- Initial access through exposed services.
- Suspicious authentication and impossible travel.
- Token abuse and session hijacking.
- Privilege escalation and role changes.
- Lateral movement between hosts or accounts.
- Command execution and persistence.
- Data staging and exfiltration.
- Defense evasion and log tampering.
This mapping exposes coverage gaps. If you cannot observe privilege changes in your cloud environment, you cannot reliably investigate cloud account takeover. If you ingest endpoint events but not identity logs, you will struggle to distinguish malware execution from stolen credential activity.
Separate alerting from evidence
Alerting is the interrupt. Evidence is the case material. They are not the same thing.
A common SOC failure is to treat the alert as the investigation. An EDR alert might tell you that a process looked suspicious. It does not answer whether the host communicated with known infrastructure, whether the user authenticated from a new geography, whether the same hash appeared elsewhere, or whether sensitive data was touched.
Design the architecture so alerts trigger evidence collection automatically. The first ticket should already include entity context, recent related events, known indicators, affected assets, owner data, and recommended pivots.
A minimal event-to-case shape can look like this:
case_type: suspected_breach
primary_entity: user_or_host
trigger_signal: alert_or_correlation
confidence: low_medium_high
required_context:
- asset_owner
- recent_authentication
- related_network_destinations
- vulnerability_exposure
- threat_intel_matches
- prior_cases
next_actions:
- confirm_entity_scope
- collect_timeline
- assess_containment_options
Keep enrichment close to the workflow
Enrichment that lives in a separate portal is often not used when the SOC is under pressure. Analysts will not pivot through five tools if the case queue is full and executives are asking for updates.
Bring enrichment into the case. That includes threat intelligence, asset criticality, vulnerability status, business owner, known exposures, historical alerts, and related observables. For a deeper architecture view, see our prior guide on threat analysis workflows that actually work.
Practical rule: Enrichment is not complete when the data exists. It is complete when the analyst can use it at the decision point without leaving the workflow.
Triage the security breach without creating a war room bottleneck
Severity is a routing decision
Severity should determine routing, not drama. If every suspicious alert becomes a P1, the SOC burns out and business partners stop taking incident channels seriously. If severity is too conservative, real breaches wait in queues while attackers keep moving.
A practical severity model should consider:
- Confidence of malicious activity.
- Criticality of affected assets or identities.
- Evidence of privilege escalation.
- Evidence of persistence.
- Evidence of data access or staging.
- Spread across multiple entities.
- Known threat actor or campaign match.
- Containment complexity.
The output should be a routing decision: monitor, investigate, escalate, contain, or declare incident. The label matters less than the action it triggers.
Use a minimum viable evidence packet
Triage needs enough evidence to route the case, not enough evidence to publish a final report. Many teams slow themselves down by trying to answer everything before declaring anything.
A minimum viable evidence packet should answer:
- What triggered suspicion?
- Which entities are involved?
- What is the strongest evidence of malicious activity?
- What is the likely attacker objective or behavior?
- What is the potential business impact?
- What action is recommended now?
This packet keeps triage from becoming an endless research task. It also helps incident commanders make decisions without reading raw logs.
Investigation workflow from suspicious signal to confirmed breach
Step by step sequence
The workflow should be explicit enough that two analysts would reach similar results. It should also be flexible enough to handle endpoint, cloud, identity, and network-led cases.
A practical sequence:
- Normalize the trigger. Capture source, timestamp, entity, alert logic, and confidence.
- Identify the primary entity. User, host, workload, API key, service account, repository, or SaaS object.
- Collect context. Asset criticality, owner, recent changes, vulnerabilities, exposure, and normal behavior.
- Build a short timeline. Focus on activity before, during, and after the trigger.
- Pivot to related entities. Shared IPs, sessions, processes, tokens, destinations, hashes, and role changes.
- Assess attacker behavior. Map observed activity to initial access, execution, persistence, escalation, movement, or exfiltration.
- Decide containment path. Choose reversible actions first unless impact or confidence justifies stronger action.
- Record decisions. Document evidence, assumptions, approvals, actions, and open questions.
The mistake teams make is letting every analyst invent this sequence every time. That creates inconsistent investigations and makes handoffs painful.
Queries and pivots that should be repeatable
Repeatability is not bureaucracy. It is how you avoid missing obvious pivots at 2 a.m.
For identity-led cases, standard pivots include:
- New device or browser fingerprint.
- New geography or ASN.
- MFA changes or failures.
- Privileged role assignments.
- OAuth app consent.
- Session token reuse.
- Password reset or recovery changes.
For endpoint-led cases, standard pivots include:
- Parent and child process tree.
- Command line arguments.
- Network destinations.
- File writes and registry changes.
- User context.
- Similar hashes across the fleet.
- Persistence mechanisms.
For cloud-led cases, standard pivots include:
- API calls by principal.
- Role assumption chain.
- Security group or firewall changes.
- Object storage access.
- Key creation or use.
- Snapshot, export, or logging changes.
Related reading from our network: cloud platform choices create similar workflow and integration tradeoffs, which is why this cloud computing software workflow guide is useful adjacent context for teams rationalizing their SaaS and infrastructure stack.
Preserve timelines as you work
Timelines are not just for post-incident reports. They are live decision tools.
A good timeline shows:
- First known suspicious activity.
- First detection time.
- First analyst review.
- Escalation time.
- Containment actions.
- Confirmed impacted entities.
- Recovery actions.
- Remaining unknowns.
What breaks in practice is that analysts keep timeline fragments in separate notes, SIEM tabs, screenshots, and chat messages. When leadership asks what happened, the team spends an hour reconstructing the story instead of responding.
Containment and response as controlled change
Containment is not just blocking
Containment is a change to a production system under uncertainty. Treat it that way.
Blocking an IP may be harmless, or it may break a partner integration. Isolating a host may stop lateral movement, or it may take down a critical process. Revoking sessions may force reauthentication, or it may interrupt an executive during a board meeting. Disabling a service account may stop abuse, or it may break deployment automation.
None of that means you should delay containment. It means containment actions need preapproved patterns, rollback plans, and impact notes.
Common containment actions include:
- Isolate endpoint.
- Disable account.
- Revoke sessions and tokens.
- Rotate credentials.
- Block domains, IPs, hashes, or certificates.
- Disable suspicious OAuth applications.
- Remove malicious forwarding rules.
- Freeze privileged role changes.
- Restrict network paths.
- Snapshot systems for forensics.
Practical rule: Prefer reversible containment when confidence is moderate, and decisive containment when attacker control or data access is credible.
Validate the blast radius
Containment does not end the investigation. It changes the investigation question from what is happening now to what else was touched.
Blast radius validation should cover:
- Other systems accessed by the same identity.
- Other identities used on the same host.
- Other hosts contacting the same infrastructure.
- Other cloud resources modified by the same principal.
- Other repositories, secrets, or storage objects accessed.
- Other alerts matching the same pattern.
This is where proactive security and incident response meet. Vulnerability exposure, attack surface data, asset inventory, and threat intelligence all help determine whether the confirmed case is isolated or part of a larger campaign.
Related reading from our network: decentralized and distributed workloads introduce operational trust boundaries that security teams should understand; this cloud computing services architecture guide is a useful adjacent lens.
What breaks when security breach workflows are built badly
Failure modes operators see
Bad breach workflows fail in predictable ways.
- Alert-only thinking: The team focuses on the detection that fired and misses related activity.
- Tool swivel: Analysts spend more time copying indicators between tools than reasoning about the case.
- Unclear ownership: Nobody knows who can approve containment.
- Evidence drift: Screenshots and notes become stale, incomplete, or unverifiable.
- Severity inflation: Everything becomes urgent, so nothing is prioritized.
- Late enrichment: Threat intelligence arrives after the decision point.
- Manual timelines: The story is reconstructed after the incident instead of maintained during it.
- Disconnected proactive work: CTEM, vulnerability management, and SOC investigations operate as separate programs.
The result is not just slower response. It is lower confidence. Leaders ask whether the breach is contained, and the SOC can only say probably.
What works and what fails
| Area | What fails | What works |
|---|---|---|
| Signal handling | Every tool creates its own queue | Signals normalize into a shared case workflow |
| Enrichment | Analysts pivot manually into portals | Context appears inside the case automatically |
| Ownership | Approval happens through ad hoc chat | Decision rights are defined before incidents |
| Investigation | Each analyst uses personal notes | Standard pivots and timelines are maintained |
| Containment | Actions are improvised | Preapproved actions include impact and rollback |
| Metrics | Dashboards count alerts | Metrics expose queue time and decision latency |
The practical question is whether your SOC can repeat the good column when the case is noisy, ambiguous, and politically sensitive.
Metrics for reducing breach impact
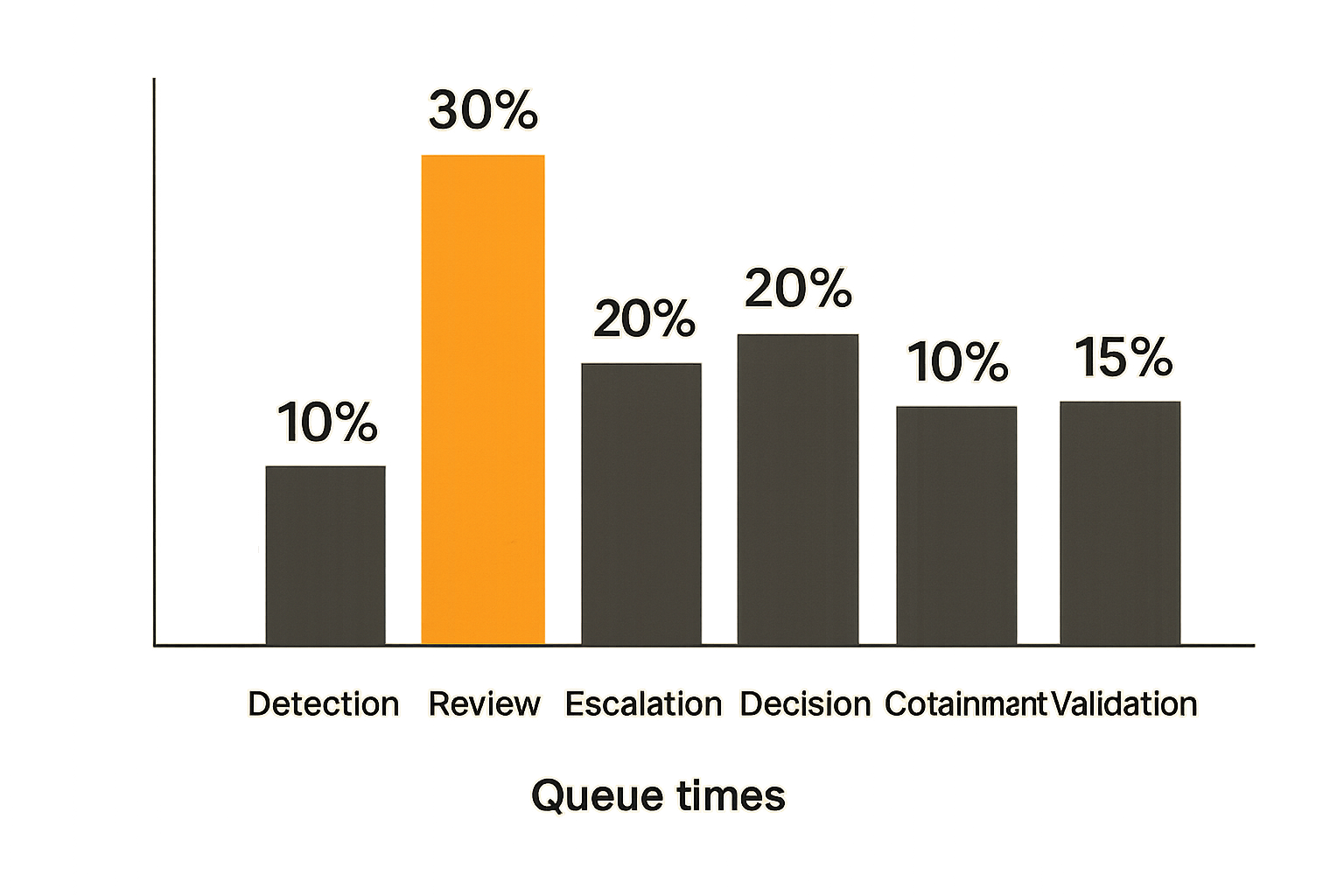
Measure time in queues
Mean time to detect and mean time to respond are useful at a high level, but they hide where work actually gets stuck. Break the workflow into queues.
Track time from:
- Event occurrence to detection.
- Detection to analyst review.
- Review to escalation.
- Escalation to decision.
- Decision to containment.
- Containment to validation.
- Validation to closure.
This lets managers fix bottlenecks. If detection to review is slow, you may have alert volume or staffing issues. If escalation to decision is slow, you likely have ownership or approval problems. If containment to validation is slow, you may lack visibility or repeatable pivots.
Measure evidence quality
Evidence quality is harder to measure than alert count, but it is more useful.
Review closed cases and ask:
- Was the primary entity clear?
- Was the timeline complete enough for handoff?
- Were pivots documented?
- Were assumptions labeled?
- Was containment tied to evidence?
- Were false positives explained in a way detection engineers can use?
Evidence quality improves detection engineering. If analysts can explain why something was benign, engineers can tune rules without simply suppressing noisy alerts.
Avoid vanity dashboards
Dashboards that show total alerts, total cases, or total blocked indicators may look productive while hiding operational weakness. A SOC can close thousands of alerts and still miss the one breach path that matters.
Better breach metrics include:
- Percentage of high-severity cases with complete evidence packets.
- Percentage of cases with entity ownership resolved automatically.
- Median decision latency by severity.
- Containment actions requiring emergency approval.
- Cases reopened because blast radius was incomplete.
- Detections tuned based on investigation feedback.
Do not optimize for looking busy. Optimize for shortening the path from credible signal to correct action.
Tooling architecture for breach-ready SOCs
Comparison of common approaches
There is no single tool that solves breach response. The architecture matters more than the label on the product.
| Approach | Strength | Weakness | Best fit |
|---|---|---|---|
| SIEM-centered | Strong log search and correlation | Can become a noisy evidence warehouse | Mature teams with query discipline |
| EDR-centered | Fast endpoint containment | Weak for SaaS, identity, and cloud-only cases | Endpoint-heavy environments |
| SOAR-centered | Good automation and orchestration | Automates bad processes if workflow is unclear | Teams with stable playbooks |
| Case-management-centered | Strong ownership and timelines | Needs good signal and enrichment inputs | SOCs improving consistency |
| CTEM-connected | Links exposure and active incidents | Requires asset and vulnerability context | Teams reducing breach paths proactively |
A useful way to think about it is that SIEM, EDR, SOAR, threat intelligence, and CTEM each provide part of the breach operating system. The problem is not that teams have multiple tools. The problem is that the handoffs between tools are unmanaged.
Integration rules that prevent swivel chair response
Integrations should reduce decisions, not just move data.
Good integrations do five things:
- Normalize entities. The same user, host, IP, domain, and cloud principal should resolve consistently.
- Attach context. Asset criticality, exposure, vulnerability, and owner data should travel with the case.
- Preserve evidence. Raw references and timestamps should remain available.
- Trigger controlled actions. Containment actions should be executable with approval and audit trails.
- Feed learning back. Investigation outcomes should update detections, suppression logic, and exposure priorities.
If an integration only creates more alerts, it is probably increasing operational load. If it reduces lookup time, improves routing, or makes containment safer, it is doing useful work.
Where ThreatCrush fits in a security breach program
Connect proactive and reactive security work
Security breach response gets stronger when the SOC understands exposure before the incident. If an alert fires on an asset that is internet-facing, unpatched, business-critical, and associated with active threat actor infrastructure, that case should not be treated like a generic alert.
Threat intelligence, vulnerability tracking, attack surface monitoring, and actor context help prioritize the right cases faster. The goal is not to decorate alerts with more data. The goal is to change routing, confidence, and containment decisions.
This is the bridge between CTEM and SOC response. Proactive work identifies where attackers are likely to succeed. Reactive work confirms whether they are succeeding now. When those workflows share context, the SOC wastes less time on low-value alerts and moves faster on credible breach paths.
Product fit for SOC teams
ThreatCrush is useful when your team is trying to reduce disconnected tooling and make threat context operational inside detection and response workflows. It is built for security operations professionals who need real-time threat intelligence, vulnerability tracking, attack surface monitoring, and threat actor context to support decisions.
That does not replace your SIEM, EDR, or case system. It should make them smarter. The architectural fit is strongest when you want threat and exposure context to influence triage, prioritization, investigation pivots, and validation.
If your SOC is still manually checking threat feeds, asset exposure, and vulnerability context during a suspected security breach, you are paying an avoidable time tax.
Try threatcrush.com
ThreatCrush is for security operations professionals building and scaling SOC capabilities. Try threatcrush.com to connect threat intelligence, exposure context, and operational workflows before the next security breach.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →