Ring Security System Architecture for SOC Teams: Signals, Workflows, and Response

A ring security system sounds like a facilities purchase until it starts generating security events at 2:14 a.m. Then the SOC owns the ambiguity: motion at a side door, camera offline, badge event missing, VPN login from the same user, and nobody knows which signal is authoritative.
Teams think the problem is buying better cameras, sensors, or alarms. The real problem is designing a workflow where physical security signals, IoT device health, identity data, and cyber telemetry can be trusted, correlated, investigated, and acted on.
That changes the conversation. A ring security system is not just a doorbell camera, a keypad, or a set of perimeter sensors. For SOC engineers and security architects, it is a distributed detection surface with messy ownership, inconsistent metadata, privacy constraints, network dependencies, and real incident response consequences.
The practical question is not whether the system can detect motion. The practical question is whether your SOC can turn the right physical signal into the right operational decision without drowning in noise.
Table of contents
- Why a ring security system is a SOC architecture problem
- Define the operating model before selecting devices
- Build the signal pipeline
- Compare ring-based monitoring with disconnected physical security
- Implementation workflow for a SOC-ready ring security system
- Detection engineering for physical and IoT events
- Incident response when physical signals meet cyber alerts
- Metrics that show whether the ring security system works
- Common failure modes
- Where threat intelligence and CTEM fit
- Closing the loop on your ring security system
Why a ring security system is a SOC architecture problem
The camera is not the control
The mistake teams make is treating the camera, contact sensor, motion detector, keypad, or alarm panel as the security control. Those are collection points. They observe something, sometimes correctly, sometimes late, and sometimes without enough context to matter.
The control is the workflow that follows the signal.
If a camera detects motion near a loading dock, the SOC needs to know whether that is expected, whether the door was opened, whether the user had access, whether nearby assets are sensitive, whether the network device for that camera is healthy, and whether the event coincides with suspicious cyber activity.
A useful way to think about it is this: physical sensors produce claims, not conclusions. The SOC has to validate those claims against identity, network, asset, and business context.
Practical rule: Treat every physical security alert as an untrusted event until it is correlated with identity, location, time, and asset context.
For a small site, that may sound heavy. In production, it is the difference between a useful alert and a stream of after-hours motion notifications nobody trusts.
The real asset is trusted event state
Most ring-style deployments focus on visibility: more cameras, more zones, more notifications. Visibility helps, but it is not enough. The real asset is trusted event state.
Trusted event state answers basic questions:
- What happened?
- Where did it happen?
- When did it happen?
- Which device reported it?
- Was the device healthy?
- Which identity or access event is related?
- What should the SOC do next?
Without state, every alert becomes a manual investigation. With state, the SOC can route the event, suppress known-benign activity, escalate real anomalies, and preserve evidence.
This is why a ring security system belongs in the same architectural conversation as SIEM, SOAR, EDR, identity, access control, asset inventory, and threat intelligence. It extends the detection surface into the physical environment, but it only creates value when it can participate in the operating model.
Define the operating model before selecting devices
Ownership boundaries
Before choosing devices, define who owns each part of the system. Facilities may own installation. IT may own network segmentation. Security engineering may own integrations. The SOC may own monitoring and escalation. Legal or compliance may own retention rules.
If those boundaries are vague, the first incident will expose the gap. The camera is offline, but the SOC has no access to the management console. The SOC sees an alert, but facilities owns the vendor relationship. Legal asks for footage, but nobody knows the retention period. The access control system has the user identity, but it is not mapped to the camera zone.
At minimum, assign ownership for:
- Device provisioning and decommissioning
- Network placement and firewall rules
- Credential and API key management
- Alert routing and severity mapping
- Evidence retention and export
- Maintenance windows
- Incident escalation
- Vendor support
The operating model should be written down before the first production alert is sent to the SOC.
Policy before placement
Device placement is usually discussed as a coverage problem. Can we see the door? Can we cover the hallway? Can we watch the parking entrance?
The better question is: what policy does this device enforce or validate?
A camera covering a server room entrance supports a different policy than a motion sensor in a lobby. A door contact on a cage containing backup media has a different escalation path than a camera watching a public reception area.
Policy-first placement prevents overcollection and under-response. It also helps explain why some signals should never page an analyst while others should trigger immediate escalation.
Use a simple mapping:
| Area | Primary risk | Signal type | SOC action | Retention need |
|---|---|---|---|---|
| Server room | Unauthorized access | Door, badge, camera | Immediate triage | Higher |
| Lobby | After-hours presence | Motion, camera | Verify and route | Standard |
| Loading dock | Asset removal | Door, camera | Correlate with schedule | Standard |
| Executive area | Targeted intrusion | Motion, camera | Escalate with identity | Higher |
| Network closet | Tampering | Door, camera, device health | Investigate quickly | Higher |
Privacy and retention as controls
Privacy is not a legal footnote. It is part of the system design.
Bad retention design creates two operational problems. First, the SOC may not have the evidence it needs when an incident is discovered late. Second, the business may retain sensitive footage longer than necessary, increasing governance risk.
The mistake teams make is using the vendor default. Vendor defaults are designed for broad adoption, not your incident response workflow.
Define retention by use case:
- Routine motion events
- Security incidents
- Access violations
- Device health logs
- Administrative actions
- Exported evidence packages
Also define who can view, export, delete, or share footage and logs. Those actions should be auditable. If a camera event can become evidence, then access to that event is itself security-sensitive.
Related reading from our network: teams facing adjacent scaling problems often discover that process boundaries matter more than the initial tool choice, as described in Scaling a Software Product.
Build the signal pipeline
Event sources you should normalize
A SOC-ready ring security system should not send raw notifications into a shared inbox and call that monitoring. It needs a signal pipeline.
Typical event sources include:
- Camera motion events
- Person or package detection events
- Door open and close events
- Alarm arming and disarming events
- Keypad activity
- Device online and offline events
- Battery, power, and tamper events
- Administrative login events
- Firmware update events
- Access control badge events
- Identity provider events
- Network telemetry for the device segment
Not every source will be available through every vendor or deployment. That is fine. What matters is that available signals are normalized into a format your SOC can search, correlate, and route.
A common event model keeps investigations sane
A common event model does not need to be complicated. It needs to be consistent.
At minimum, normalize these fields:
- event_time
- event_type
- device_id
- device_name
- site
- zone
- physical_location
- confidence
- source_system
- related_identity
- related_asset
- severity
- raw_event_reference
Example normalized event:
event_time: 2026-06-03T02:14:19Z
event_type: physical.motion.detected
device_id: cam-loading-dock-03
device_name: Loading Dock Camera 03
site: denver-office
zone: loading-dock
physical_location: north exterior dock
confidence: medium
source_system: ring_security_system
related_identity: null
related_asset: backup-media-cage
severity: low
raw_event_reference: vendor-event-89127
That structure lets the SOC ask better questions. Show me all after-hours motion events near sensitive assets. Show me cameras that went offline before a door opened. Show me access events where the badge identity does not match the expected schedule.
Enrichment makes physical signals usable
Raw physical events are noisy because they lack business context. Enrichment turns them into operational signals.
Useful enrichment sources include:
- Site calendars and business hours
- Employee schedules and access groups
- Asset criticality
- Door and camera zone maps
- Network device inventory
- Vulnerability data for camera firmware and gateways
- Known maintenance windows
- Threat intelligence related to targeted facilities or executives
This is the same pattern SOC teams use for cyber detections. An IP address becomes more useful when enriched with ownership, exposure, reputation, and recent activity. A motion event becomes more useful when enriched with zone, schedule, asset sensitivity, and device health.
For a broader SOC architecture baseline, the ThreatCrush guide to security operations in 2026 is a useful companion because the same ownership, telemetry, and response principles apply here.
Compare ring-based monitoring with disconnected physical security
What works
Disconnected physical security can work for small environments where one person reviews footage, knows every employee, and handles every alarm. That model breaks as sites, shifts, vendors, and systems multiply.
Ring-based monitoring works better when it is designed as layered signal coverage. The outer ring detects perimeter activity. The inner ring validates access to sensitive areas. Device health monitoring watches the sensors themselves. Identity and network telemetry provide context.
| Approach | Best for | Strength | Weakness | SOC implication |
|---|---|---|---|---|
| Standalone camera alerts | Small sites | Fast deployment | High noise, low context | Manual review |
| Alarm-only monitoring | Basic intrusion response | Clear escalation | Little investigative detail | External dependency |
| Integrated physical-cyber workflow | Multi-site operations | Correlation and routing | Requires architecture | SOC-operable |
| Fully automated response | Mature environments | Fast containment | Risk of bad automation | Needs strong validation |
The point is not to automate everything. The point is to preserve enough context that analysts do not start every investigation from zero.
Practical rule: Do not connect a physical security tool to the SOC until you know which alerts require human action and which should only update state.
What fails
What breaks in practice is notification-driven operations. A vendor app sends alerts to a few phones. A shared mailbox receives clips. A facilities manager forwards a screenshot. The SOC opens a ticket with incomplete context. Nobody knows whether the issue was resolved.
That model fails because it has no durable state, no measurable queue, and no consistent escalation path.
Common symptoms include:
- Analysts ignore motion alerts because most are benign
- Facilities assumes the SOC saw something the SOC never received
- Access control logs are reviewed hours after footage expires
- Camera outages are discovered during an incident
- Evidence exports are inconsistent
- Automation suppresses alerts without documenting why
A ring security system can reduce uncertainty, but only if it is wired into an operational workflow rather than treated as a set of standalone gadgets.
Related reading from our network: the architecture issues are different, but the lesson that state, retries, and operational reconciliation matter more than UI is also central to Crypto Payments in 2026.
Implementation workflow for a SOC-ready ring security system

Sequence the work in layers
Do not start with every site, every camera, and every possible alert. Start with a high-value use case and build the pipeline end to end.
A practical implementation sequence:
- Select one critical zone. Choose a server room, network closet, loading dock, or restricted office area.
- Document the policy. Define what normal and abnormal access looks like.
- Inventory devices. Record cameras, sensors, gateways, network segments, owners, firmware, and admin accounts.
- Normalize events. Send device, alarm, access, and health events into a common schema.
- Add enrichment. Join events with site, zone, asset criticality, schedule, and identity context.
- Create detection logic. Start with a small number of high-confidence detections.
- Define response paths. Decide who investigates, who validates on site, and who closes the loop.
- Test with simulations. Run controlled events during and after business hours.
- Measure and tune. Track noise, missed events, response time, and analyst effort.
- Expand by zone. Add more coverage only after the first workflow is stable.
This sequence keeps teams from confusing deployment with adoption. Devices can be installed in a week. A reliable SOC workflow takes design.
Integration checklist
Your integration checklist should cover both telemetry and control-plane security.
Do these before production:
- Confirm API access or export method
- Verify event timestamp accuracy and timezone handling
- Create unique device IDs and stable names
- Map devices to physical zones
- Map zones to asset criticality
- Segment IoT devices from corporate endpoints
- Monitor device online and offline state
- Audit administrative logins
- Rotate API credentials
- Define retention and export procedures
- Test alert delivery during vendor outage scenarios
- Document escalation contacts by site
Practical rule: If the SOC cannot tell whether a camera was online at the time of an incident, the camera is not a reliable control.
Testing before production
Testing should include normal activity, abnormal activity, and system failure.
Run test cases such as:
- Authorized employee enters during business hours
- Authorized employee enters after hours
- Door opens without matching badge event
- Motion occurs near a sensitive asset after hours
- Camera goes offline before a door event
- Gateway loses network connectivity
- Alarm is disarmed by an unexpected account
- Footage export is requested for an incident
- Vendor API rate limits or delays events
The goal is not a perfect lab. The goal is to find the operational gaps before they happen under pressure.
Good tests answer: did the event arrive, was it enriched, did the right detection fire, did the right person get notified, was the evidence preserved, and did the ticket close with enough detail to improve the workflow?
Detection engineering for physical and IoT events
Useful detections
Detection engineering for a ring security system should start boring. Boring detections are easier to validate and less likely to produce analyst fatigue.
Useful starting detections include:
- Motion in restricted zone outside approved hours
- Door open without corresponding badge access
- Camera offline followed by nearby access event
- Repeated failed keypad attempts
- Alarm disarmed by dormant or unexpected account
- Device firmware below approved version
- New administrative user added to console
- Camera moved, tampered with, or renamed
- Unusual access pattern for privileged employee
- Multiple sites reporting device outage simultaneously
Each detection needs an owner, severity, expected action, and tuning plan.
A weak detection says: motion detected. A better detection says: after-hours motion detected in a high-criticality zone where no approved maintenance window exists and the nearest access control event does not map to an authorized identity.
Correlation logic
Correlation is where the ring security system becomes useful to the SOC.
Examples:
rule: after_hours_sensitive_zone_motion
when:
event_type: physical.motion.detected
zone_criticality: high
business_hours: false
maintenance_window: false
then:
severity: medium
action: create_soc_case
rule: camera_offline_before_access
when:
event_type: physical.door.opened
zone_criticality: high
nearby_camera_status_within_10m: offline
then:
severity: high
action: escalate_to_soc_and_site_contact
rule: physical_and_cyber_identity_collision
when:
physical_access_identity: user_a
vpn_login_identity: user_a
impossible_travel_window: true
then:
severity: high
action: investigate_identity_compromise
The last example is where physical and cyber monitoring become more than the sum of their parts. A badge event in one city and a VPN session from another region may indicate credential misuse, badge sharing, compromised identity, or bad data. The SOC still has to investigate, but it starts with a stronger hypothesis.
Tuning without hiding real incidents
Tuning should reduce noise without deleting context. The mistake teams make is suppressing alerts too broadly because the first week is noisy.
Better tuning options include:
- Lower severity instead of full suppression
- Suppress only during approved schedules
- Require multiple signals for escalation
- Route low-confidence events to daily review
- Keep state updates searchable even when not alerting
- Add zone-specific thresholds
- Track suppressions as configuration changes
Never tune by analyst annoyance alone. Tune by business context and measured false-positive patterns.
If a motion detector fires every night because cleaning staff pass through a hallway, update the schedule and identity mapping. Do not globally suppress after-hours motion.
Incident response when physical signals meet cyber alerts
Triage model
Physical security events need a triage model that fits SOC operations. A useful triage path is:
- Validate signal integrity
- Confirm device health
- Review related physical events
- Review related identity events
- Review related cyber telemetry
- Contact site owner if needed
- Preserve evidence if suspicious
- Escalate based on impact
The first question should often be whether the signal is trustworthy. If a device was offline, recently moved, or generating errors, the investigation changes. If the device is healthy and the event correlates with other signals, severity rises.
A ring security system should also support negative evidence. No badge event, no maintenance window, no expected schedule, and no camera outage can all matter.
Escalation paths
Escalation should not depend on who happens to see a push notification.
Define paths by event class:
- Device health issue: IT or facilities owner
- Routine after-hours motion: SOC review or site contact
- Restricted zone access anomaly: SOC escalation
- Evidence request: incident commander or legal-approved process
- Possible physical intrusion: SOC plus local response plan
- Identity collision: SOC plus identity team
- Vendor compromise concern: security engineering plus procurement
For mature SOCs, these paths should live in the case management or SOAR system. For smaller teams, a documented runbook is still better than improvisation.
The ThreatCrush article on threat analysis workflows maps well to this problem because the hard part is not listing analysis steps; it is connecting them so an alert becomes an investigation instead of a handoff chain.
Evidence handling
Evidence handling is where many physical security deployments become fragile.
You need answers to basic questions:
- Who can export footage?
- Is the export watermarked or signed?
- Are timestamps preserved?
- Is the original event retained?
- Is access to the evidence logged?
- Can evidence be attached to an incident case?
- What happens when retention expires?
For internal investigations, the standard may be operationally sufficient. For legal, HR, fraud, insider threat, or law enforcement workflows, evidence handling needs tighter controls.
Do not wait for a serious incident to test this. Run an evidence export drill and time how long it takes to produce a complete package with event metadata, related logs, and chain-of-access notes.
Metrics that show whether the ring security system works
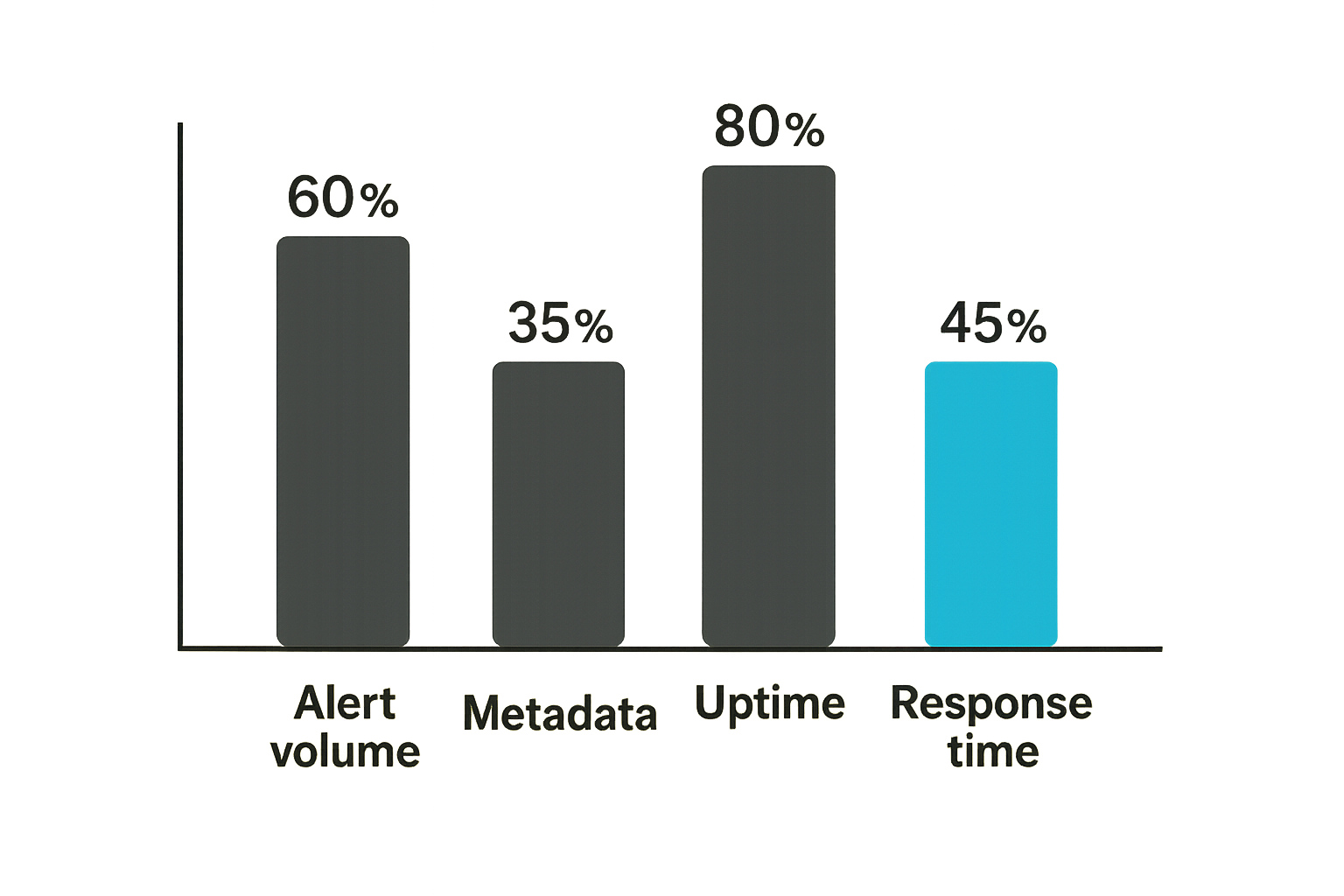
Signal quality
If you do not measure signal quality, you will optimize for activity instead of outcomes.
Track metrics such as:
- Alert volume by site and zone
- False-positive rate by detection
- Percentage of events with complete metadata
- Percentage of devices with known owner
- Device uptime by criticality
- Events missing zone mapping
- Events missing identity correlation
- Suppression count by rule
These metrics show whether your ring security system is becoming more reliable or just louder.
Signal quality also helps justify engineering work. If 35 percent of high-priority physical events lack zone mapping, the next improvement is not a new camera. It is data hygiene.
Response time
Response time should be measured across the workflow, not just alert delivery.
Useful timestamps include:
- Event observed
- Event received by SOC platform
- Alert created
- Analyst acknowledged
- Context enriched
- Site contact engaged
- Evidence preserved
- Case resolved
Each timestamp exposes a different bottleneck. Vendor API delay is different from analyst queue delay. Missing site contacts are different from slow enrichment. Without this breakdown, teams argue from anecdotes.
Practical rule: Measure the time from physical event to operational decision, not just the time from alert creation to analyst acknowledgement.
Coverage gaps
Coverage gaps are not only camera blind spots. They include missing ownership, missing telemetry, missing response paths, and missing context.
Track coverage by asking:
- Which sensitive zones have no monitored sensor?
- Which sensors have no SOC integration?
- Which devices have no owner?
- Which zones have no documented response path?
- Which alerts cannot be correlated with identity?
- Which devices are unsupported or end of life?
- Which sites have retention that does not match incident needs?
This is where physical security connects directly to continuous threat exposure management. Exposure is not only internet-facing infrastructure. It is also the operational gap between an important asset and the controls that should protect it.
Common failure modes
Notification spam
Notification spam is the most common failure mode. It usually happens when teams forward vendor alerts directly to analysts without severity mapping, enrichment, or suppression logic.
The result is predictable. Analysts stop trusting the feed. Real events hide inside routine motion. Facilities and SOC teams blame each other. Leadership sees dashboards full of activity but no clear risk reduction.
Fix it by separating event ingestion from alerting. Ingest broadly. Alert selectively. Keep low-priority events searchable, but do not page humans for every state change.
Blind spots
Blind spots appear when coverage is designed by floor plan instead of risk.
A hallway may have three cameras while the network closet has a weak sensor and no device health monitoring. A loading dock may have excellent video but no correlation with shipment schedules. An executive area may have cameras but no clear escalation path after hours.
Blind spots also appear in the network layer. Many camera and alarm devices live on IoT segments that are poorly inventoried, inconsistently patched, or excluded from normal monitoring. If a device can observe sensitive activity, its own compromise matters.
Broken ownership
Broken ownership is the failure mode that causes the longest delays.
The SOC sees the alert but cannot access the console. Facilities can access footage but cannot interpret cyber context. IT owns the network but not the vendor. Legal owns retention but is not in the incident workflow. Procurement owns the contract but not the risk.
The fix is boring and necessary: an ownership matrix, named contacts, documented escalation, and periodic drills.
Related reading from our network: even outside security, local operating models fail when asks, routing, trust, and follow-up are not explicit; that pattern is explored in Community Action in 2026.
Where threat intelligence and CTEM fit
From device inventory to exposure
Threat intelligence and CTEM matter because a ring security system introduces more devices, more cloud dependencies, more administrative accounts, and more vendor risk.
A camera is not only a sensor. It is also an endpoint-like device with firmware, credentials, network access, cloud connectivity, and management APIs. An alarm console is not only a panel. It is part of the security control plane.
Your exposure view should include:
- Device models and firmware versions
- Known vulnerabilities
- Publicly exposed management interfaces
- Vendor cloud dependencies
- Administrative users and MFA status
- Network segmentation
- Sites with weak monitoring coverage
- Devices protecting high-criticality zones
This lets teams prioritize remediation. A vulnerable camera in a public lobby is one thing. A vulnerable gateway connected to cameras covering sensitive areas is another.
Connect proactive and reactive work
The practical question is how to connect proactive exposure work with reactive SOC work.
If CTEM finds a vulnerable device in a critical zone, the SOC should know that events from that device may be less trustworthy. If the SOC sees a camera offline before a restricted access event, exposure context should show whether that device has known reliability issues, weak firmware, or suspicious network behavior.
This is where many organizations still run disconnected tooling. Asset inventory lives in one place. Threat intelligence lives somewhere else. SOC cases live in another queue. Physical security events live in a vendor console. The analyst becomes the integration layer.
That does not scale.
A better model connects:
- Asset and device inventory
- Vulnerability and exposure data
- Physical security telemetry
- Identity and access events
- Network monitoring
- SOC case management
- Threat intelligence
The objective is not a giant dashboard. The objective is shorter investigation time and better decisions.
Product fit for ThreatCrush
ThreatCrush is a fit when your team is trying to connect threat intelligence, vulnerability context, attack surface monitoring, and operational workflows instead of adding another disconnected feed.
For a ring security system, that means security teams can think beyond the motion alert. Which devices are exposed? Which vulnerabilities matter? Which zones are high impact? Which signals should influence SOC triage? Which issues should be handled proactively before an incident depends on that control?
This is not about replacing physical security platforms. It is about making their signals more useful inside a modern SOC architecture.
If you are building these workflows, the goal is to reduce noise, shorten investigation time, and connect proactive and reactive work. That is the same operating problem ThreatCrush is built around.
Closing the loop on your ring security system
Decision criteria
A ring security system should be judged by operational fit, not by the number of devices installed.
Use these criteria before expanding:
- Can the SOC receive normalized events?
- Are devices mapped to zones and owners?
- Are high-value zones tied to clear policies?
- Can alerts be correlated with identity and cyber telemetry?
- Are device health events monitored?
- Are detections tuned by context rather than annoyance?
- Are escalation paths documented and tested?
- Can evidence be preserved and audited?
- Are exposure and vulnerability issues visible?
- Do metrics show improving signal quality?
Teams think the problem is picking the right ring security system. The real problem is building a trustworthy signal and response architecture around it.
Closing the loop means every important event has a path: observe, normalize, enrich, correlate, decide, respond, preserve, learn. If that path is missing, the system is just another source of noise. If that path exists, the ring security system becomes part of the SOC operating model.
Try threatcrush.com
ThreatCrush is for security operations professionals building and scaling SOC capabilities. Connect threat intelligence, exposure context, and operational workflows so your team can act faster with less noise.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →