Peptide Threat Detection: A Practical SOC Architecture for Biosecurity Workflows

Peptide threat detection sounds like a niche biosecurity term until your SOC has to triage an alert from a peptide design platform, a cloud notebook, a synthesis vendor portal, and an identity provider in the same hour.
The first problem is not that analysts lack effort. It is that the workflow does not look like normal enterprise intrusion detection. The same user may move between sequence design, model inference, procurement, LIMS, object storage, and external collaboration. One noisy alert rarely explains intent.
Teams think the problem is finding the perfect peptide threat detection rule. The real problem is connecting scientific context, identity behavior, data movement, and response ownership into one operating model.
That changes the conversation. This guest post is written by the team at coinpayportal.com, where we spend a lot of time thinking about stateful systems, trust boundaries, reconciliation, and abuse detection in infrastructure that cannot afford ambiguous ownership. The same discipline applies here: the UI is not the system, the alert is not the incident, and the workflow is where detection either works or breaks.
Table of contents
- Peptide threat detection is a workflow problem
- Define the assets before writing detections
- Build the detection architecture around signals
- Model attacker intent, not just indicators
- Turn peptide threat detection into SOC workflows
- Use automation carefully
- What breaks when teams implement it badly
- Metrics that actually help
- Product fit for ThreatCrush-style operations
- Closing the loop on peptide threat detection
Peptide threat detection is a workflow problem
Peptide threat detection is not a magic classifier that labels a sequence as good or bad. In production, it is a SOC capability for watching how peptide-related work is designed, accessed, moved, approved, shared, and purchased.
That matters because peptide programs are rarely contained in one system. A research team may use SaaS tools, custom notebooks, model APIs, cloud GPU jobs, Git repositories, sequence databases, ELNs, LIMS platforms, storage buckets, procurement tools, and external synthesis partners. Each system sees a slice. The SOC needs the story.
A useful way to think about it is this: peptide threat detection is the security layer around a scientific supply chain.
What makes peptide environments different
Peptide environments combine normal enterprise risk with domain-specific abuse paths. The SOC still cares about account takeover, malware, insider activity, credential theft, and cloud misconfiguration. But the consequences and intent signals can look different.
A suspicious event may be:
- An unusual download of sequence libraries.
- A new API key used from an unmanaged notebook host.
- A researcher account accessing projects outside its normal therapeutic area.
- A batch export immediately followed by upload to an external collaboration tool.
- A synthesis order placed through a vendor workflow that bypasses normal review.
- A cloud job generating sequence variants at a scale that does not match the project plan.
None of these are automatically malicious. That is the hard part. They become meaningful when linked to identity, project context, approval state, data classification, and external movement.
Practical rule: Treat peptide activity as a business process with security controls, not as a collection of isolated application logs.
Why ordinary SOC rules miss the point
Ordinary SOC detections often assume familiar endpoints: suspicious PowerShell, impossible travel, command-and-control domains, privilege escalation, or malware execution. Those still matter. But peptide threat detection needs additional context that most SIEM content does not have by default.
The mistake teams make is applying generic exfiltration thresholds to scientific workflows. A legitimate model training run may read millions of records. A legitimate collaboration may export a project folder. A legitimate vendor integration may call an API at odd hours.
What breaks in practice is precision. Analysts see noise, tune the rule down, and then the program loses coverage exactly where it needs it: unusual but plausible behavior.
Define the assets before writing detections
Before writing a single rule, define what must be protected and why. This sounds basic, but it is where many peptide threat detection projects fail. They start with logs because logs are available. They should start with workflow ownership.
The practical question is not, what can we detect? It is, what activity would create unacceptable risk if it happened without authorization, review, or business context?
Map the scientific workflow
Start with the path from idea to external action. In a peptide environment, that might look like:
- Research hypothesis or target selection.
- Sequence design or variant generation.
- Model scoring or filtering.
- Storage of candidate libraries.
- Review by project or safety owner.
- Export to collaboration, procurement, or synthesis.
- Vendor communication and fulfillment.
- Downstream lab validation.
This map gives detection engineers the control points. Each step should have owners, systems, identities, logs, and expected behaviors.
Do not skip external systems. Vendor portals, shared drives, contract research organization handoffs, and managed lab platforms are often where detection visibility gets thin. If the SOC cannot see an action directly, it should at least see the upstream approval and downstream reconciliation.
Separate data sensitivity from system criticality
A highly sensitive peptide library may live in a boring storage bucket. A critical LIMS platform may contain mixed sensitivity data. A notebook environment may be low criticality until it mounts a protected dataset.
Use two classifications:
| Dimension | Question | Detection impact |
|---|---|---|
| Data sensitivity | What information could be misused or cause business harm? | Drives monitoring depth and export controls |
| System criticality | What process depends on this service? | Drives response urgency and containment rules |
| Workflow position | Is this before or after approval? | Drives triage severity |
| External reach | Can this action leave the organization? | Drives escalation and notification |
This prevents a common false assumption: that the most important detections are always on the most important systems. Sometimes the best signal is a low-profile storage event, a forgotten API token, or a vendor account login.
Practical rule: Classify peptide assets by data, system, workflow stage, and external reach. One label is not enough for useful detection.
Build the detection architecture around signals
Once assets are mapped, build around signal families. This is where security architects should be strict. If a detection cannot be tied to a signal source, an owner, and a response action, it is not operational yet.
Peptide threat detection usually needs four signal layers: identity, application activity, data movement, and infrastructure behavior. The SOC should correlate them instead of asking analysts to pivot manually across five consoles.
Identity and access signals
Identity is the first control plane. Most suspicious peptide activity becomes clearer when viewed through account posture.
Collect and normalize:
- SSO events for researchers, contractors, service accounts, and vendors.
- MFA changes, device trust, session age, and conditional access decisions.
- Group membership changes for sensitive projects.
- Privileged role assignments in cloud, notebook, LIMS, and storage systems.
- API key creation, token scope changes, and unused credential reactivation.
Good identity detections ask whether the user is behaving consistently with their role and project. Bad identity detections only ask whether the login came from a new country.
Examples that tend to be useful:
- A contractor account gets access to a restricted sequence repository outside its contract project.
- An old service account creates new storage read permissions.
- A user changes MFA, logs in from a new device, and exports a peptide library within a short window.
- A project admin adds a personal email account or unmanaged identity to a collaboration space.
Data and pipeline signals
The second layer is movement through scientific systems. This is not just DLP. It is pipeline-aware monitoring.
Useful signals include:
- Dataset reads by project, user, and compute job.
- Sequence export events by file type, size, destination, and approval state.
- Notebook execution against sensitive libraries.
- Object storage access patterns, especially bulk listing and cross-region copy.
- Git clone, branch, and secret exposure events for peptide-related repositories.
- Model API calls that generate or score large batches outside normal schedules.
Detection engineers should create a normalized event model. A simple schema helps:
actor, asset, project, action, workflow_stage, approval_state, destination, volume, tool, source_ip, device_state, timestamp.
That structure is not glamorous, but it shortens investigations. Analysts stop asking what the event means and start asking whether the behavior is authorized.
Practical rule: Normalize peptide workflow events into business actions. A raw API call is rarely enough context for an analyst.
Model attacker intent, not just indicators
Threat intel for peptide environments should not stop at IOCs. Domains, hashes, and IPs are useful, but the higher-value model is intent: what would an attacker or malicious insider try to accomplish?
For many teams in 2026, the answer includes theft of proprietary research, sabotage of experimental workflows, unauthorized synthesis, model abuse, and disruption of regulated operations. The SOC does not need to become a biology review board. It does need to know which behaviors represent unacceptable paths.
Reconnaissance and privilege shaping
Early attacker behavior may look like exploration. In a peptide workflow, that could include browsing project names, listing storage buckets, opening old notebooks, querying metadata tables, or checking vendor integrations.
Look for combinations:
- First-time access to peptide projects plus broad search activity.
- Repository enumeration followed by permission requests.
- Service account discovery followed by token creation.
- Notebook environment creation followed by mounting sensitive datasets.
- Access to safety review records by accounts that normally only handle analysis.
Privilege shaping is especially important. Attackers often do not need domain admin. They need just enough access to pull a dataset, alter a workflow, or submit an external request.
Exfiltration and misuse paths
Exfiltration in peptide programs can be subtle. A few files may matter more than a terabyte. A model prompt, candidate list, scoring output, or vendor order may be the valuable artifact.
Watch for:
- Compression or packaging of project folders before export.
- Download of candidate libraries immediately after access changes.
- Copy from controlled storage to personal cloud or unmanaged collaboration tools.
- External sharing with domains not associated with approved partners.
- Unusual synthesis request patterns, especially outside approved workflows.
- Deletion or modification of review artifacts after export.
The goal is not to block science. The goal is to make unauthorized movement visible quickly enough to respond.
Turn peptide threat detection into SOC workflows
Detection content is only useful if the SOC knows what to do next. This is where peptide threat detection becomes an operating model rather than a dashboard.
The analyst should not need to understand every peptide domain detail. The workflow should provide enough context to decide whether to escalate, contain, request business validation, or close as expected activity.
A practical investigation sequence
Use a repeatable sequence. Do not let every alert become a custom research project.
- Confirm the actor. Validate identity, device posture, session history, role, and recent access changes.
- Identify the asset. Determine whether the asset is sensitive, critical, pre-approval, post-approval, or externally reachable.
- Reconstruct the workflow. Place the action in sequence: design, analysis, export, review, procurement, vendor transfer, or lab validation.
- Check authorization. Compare the action to project membership, ticketing, approval records, change windows, or collaboration agreements.
- Assess movement. Determine whether data, code, model output, or instructions left a controlled boundary.
- Contain proportionally. Disable tokens, revoke sharing, pause vendor submission, isolate notebook sessions, or require step-up verification.
- Document the decision. Capture why the event was expected, suspicious, or confirmed.
This sequence is simple by design. It gives Tier 1 and Tier 2 analysts a path that does not depend on tribal knowledge.
Triage questions analysts can answer
Build the alert around questions the analyst can answer in minutes:
- Is the actor a human, service account, vendor account, or automation?
- Is this actor normally associated with the project?
- Was access granted recently?
- Is the data classified as restricted, controlled, or public?
- Did the action move information outside an approved system?
- Was there an approval or ticket near the event time?
- Has this pattern happened before for this project?
- Who owns the business decision if containment affects research?
If the alert does not answer at least half of these, the detection is under-instrumented.
Practical rule: Every peptide threat detection alert should include actor, asset, workflow stage, authorization context, and a containment owner.
Use automation carefully
Automation helps when it enriches, correlates, and contains reversible risk. It hurts when it blocks scientific work without context or silently suppresses edge cases.
Security teams should be skeptical of fully autonomous decisions in peptide workflows unless the blast radius is well understood. The best automation usually reduces analyst time without pretending to replace judgment.
What to automate first
Start with enrichment and correlation:
- Pull project ownership into the alert.
- Add asset classification and workflow stage.
- Join identity changes from the previous 24 to 72 hours.
- Attach recent data movement and external sharing events.
- Show vendor or partner allowlist status.
- Add related cloud, notebook, and repository activity.
Then automate low-risk containment:
- Revoke a newly created unused token.
- Disable external share links pending review.
- Require step-up authentication for a suspicious session.
- Pause a queued external transfer until a project owner approves.
- Snapshot logs and preserve notebook state for investigation.
These actions are useful because they are reversible or bounded. They buy time.
Where automation can cause damage
Do not blindly kill compute jobs, delete files, or lock out research teams without a tested escalation path. In some environments, interrupting a lab workflow can destroy experimental continuity, delay regulated work, or create safety issues.
What fails is binary thinking: malicious or benign, block or ignore. Many peptide alerts live in the gray zone. The right action is often pause, verify, and resume.
A safer automation pattern is:
- Observe: enrich and correlate.
- Friction: require re-authentication or owner approval.
- Contain: revoke access or stop movement when risk is high.
- Recover: restore access with documented authorization.
That pattern supports security without turning the SOC into an arbitrary gatekeeper.
What breaks when teams implement it badly
Bad peptide threat detection does not fail loudly at first. It fails as analyst fatigue, ignored alerts, blind spots around external workflows, and delayed response when something actually matters.
The mistake teams make is buying or building a narrow detector and calling the program done. The detector may be useful, but the program still needs signal quality, workflow context, response owners, and validation.
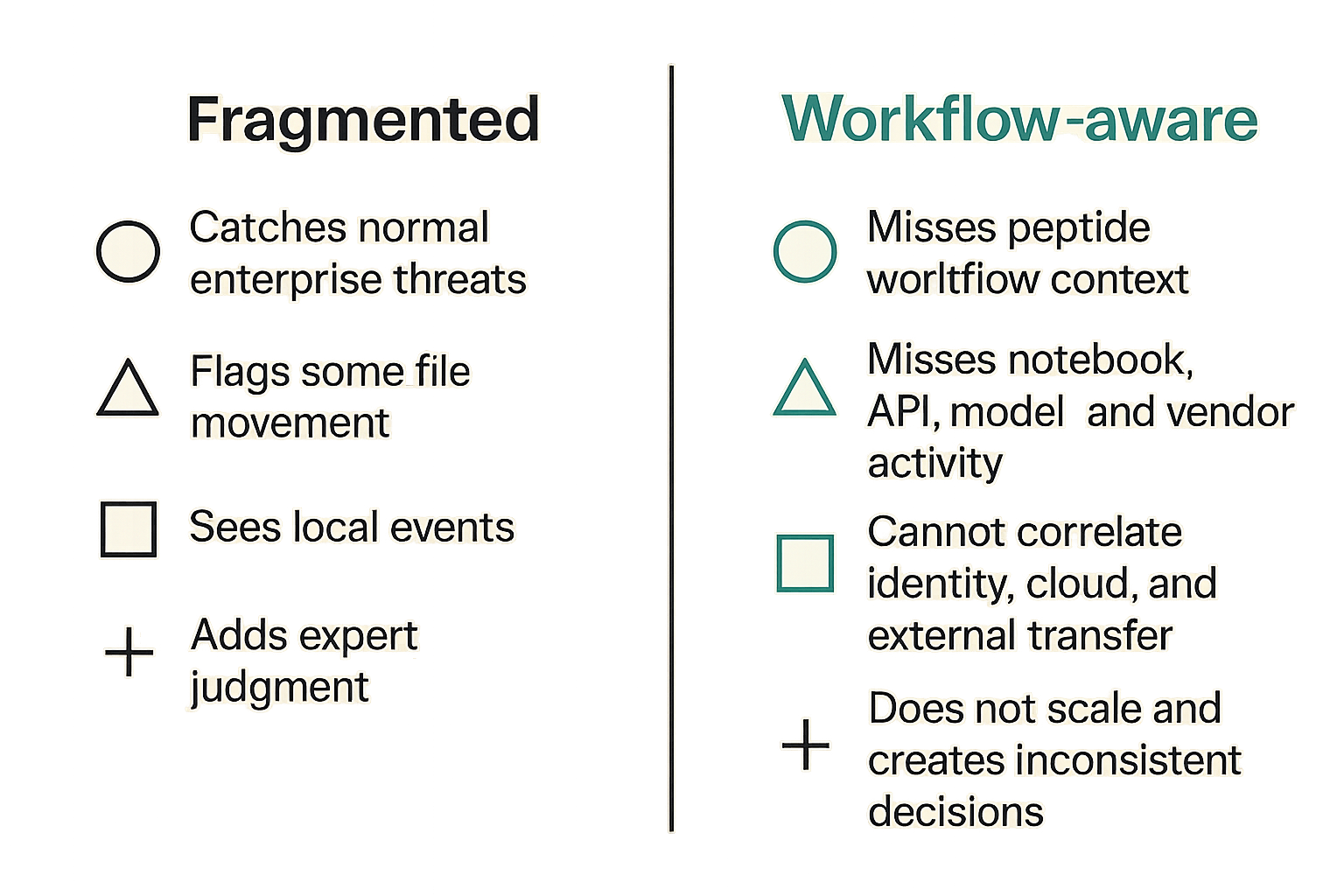
Failure mode comparison
| Approach | What works | What fails |
|---|---|---|
| Generic SIEM only | Catches normal enterprise threats | Misses peptide workflow context |
| DLP only | Flags some file movement | Misses notebook, API, model, and vendor activity |
| App alerts only | Sees local events | Cannot correlate identity, cloud, and external transfer |
| Manual review only | Adds expert judgment | Does not scale and creates inconsistent decisions |
| Workflow-aware SOC | Connects signals to ownership | Requires mapping, tuning, and maintenance |
The practical answer is not more tools. It is better joins between tools.
The ownership gap
The ownership gap is the most common operational failure. Security owns the alert. Research owns the project. IT owns identity. Platform owns cloud. Procurement owns vendor systems. Legal or compliance may own external reporting.
During an incident, that fragmentation burns time.
Fix it before the alert fires:
- Assign an owner for each sensitive peptide workflow.
- Define who can approve emergency containment.
- Document which systems can be paused safely.
- Pre-stage vendor contact paths.
- Maintain project-to-identity mappings.
- Review external sharing exceptions regularly.
If nobody can authorize action at 2 a.m., the detection is not operational.
Metrics that actually help
Peptide threat detection metrics should reflect decision quality, not dashboard activity. Alert volume is a weak proxy. A low-volume program can still miss the important path. A high-volume program can still be useless.
The useful metrics are about context, speed, and validation.
Measure context, not alert volume
Track metrics like:
- Percent of alerts with project owner attached.
- Percent of alerts with asset classification attached.
- Median time to reconstruct workflow stage.
- Median time to determine whether data left a controlled boundary.
- Percent of alerts resolved with documented business authorization.
- Number of detections mapped to external movement paths.
- Number of sensitive workflows with no telemetry coverage.
These metrics tell you whether the SOC can make decisions. That is the point.
A small chart for leadership can be blunt: context coverage, response speed, and blind spots. Avoid vanity reporting.
Validation and tuning cadence
Detection content decays. Research teams change tools. New vendors appear. Cloud pipelines move. Model workflows evolve. A rule that worked last quarter may be blind this quarter.
Run a quarterly validation cycle:
- Pick one sensitive workflow.
- Walk through expected activities with the business owner.
- Confirm telemetry exists at each step.
- Run safe simulations for access change, export, external share, and token creation.
- Measure alert context and response time.
- Tune thresholds and suppression rules.
- Update ownership and runbooks.
This is continuous threat exposure management applied to a domain workflow. It is not glamorous, but it prevents the program from becoming shelfware.
Product fit for ThreatCrush-style operations
A ThreatCrush-style approach should sit between raw telemetry and SOC action. The value is not another alert feed. The value is connecting proactive exposure work with reactive investigation.
Peptide threat detection needs that bridge because the risk is cross-domain. Identity posture, cloud exposure, data movement, application behavior, and incident response all matter.
Where a platform should sit
The platform should integrate with:
- SIEM or data lake for normalized event storage.
- SOAR or case management for response workflows.
- Identity provider for users, groups, roles, and sessions.
- Cloud platforms for storage, compute, IAM, and audit logs.
- Scientific applications where logs are available.
- Ticketing and approval systems for business context.
- Threat intelligence and exposure data for prioritization.
The key is not replacing every system. It is making the SOC workflow coherent.
A useful platform should answer: what happened, why it matters, who owns it, what changed recently, what can be done safely, and how we know the response worked.
What a useful integration looks like
A useful integration does four things:
- Normalizes events into actor, asset, action, project, and destination.
- Enriches alerts with identity posture, asset sensitivity, and workflow stage.
- Links cases to owners, approvals, and prior related activity.
- Validates controls by testing whether telemetry and runbooks still work.
That is the architecture operators need. Not a black box. Not a biology-themed alert label. A workflow engine for detection, context, and response.
Closing the loop on peptide threat detection
Peptide threat detection will keep becoming more relevant as bioinformatics workflows, cloud platforms, model-assisted design, and external research networks become more connected. The risk is not limited to one application or one data store.
Teams think the problem is finding the perfect detector. The real problem is building a SOC workflow that understands identity, scientific context, data movement, external reach, and ownership.
The operating model to keep
Keep the model simple:
- Map the workflow before writing rules.
- Classify assets by sensitivity, criticality, stage, and external reach.
- Normalize events into business actions.
- Correlate identity, data, application, and infrastructure signals.
- Automate enrichment before containment.
- Validate coverage every quarter.
- Measure decision quality instead of alert volume.
If you do that, peptide threat detection becomes manageable. It becomes a practical operating capability rather than a vague biosecurity aspiration.
Try threatcrush.com
ThreatCrush helps security teams connect signals, workflows, detection, and response without turning every investigation into a manual console crawl. Try threatcrush.com for practical SOC operations around modern threat detection, including peptide threat detection use cases.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →