Peptide Security Operations: A Practical SOC Architecture for Biotech, Labs, and Manufacturing

Peptide security operations sounds narrow until the first alert hits a live research workflow, a manufacturing batch, or a partner file exchange that nobody in the SOC fully understands.
Teams think the problem is lab endpoint security. The real problem is operational context: which instrument matters, which dataset is regulated or high-value, who owns the workflow, and what containment action will stop the attacker without ruining science or production.
That changes the conversation. The practical question is not whether you have EDR, SIEM, identity logs, or vulnerability data. The question is whether those signals become decisions fast enough for a peptide discovery, synthesis, QA, or manufacturing environment where data integrity and continuity matter as much as confidentiality.
This post treats peptide security operations as an architecture and workflow problem. Not a definition. Not a tool category. A working SOC model for environments where lab systems, cloud compute, intellectual property, partners, and regulated operations collide.
Table of contents
- Peptide security operations is a workflow problem, not a lab tool problem
- Build the asset and data model before writing detections
- Reference architecture for peptide security operations
- Detection engineering for peptide environments
- Workflow design from alert to containment
- What breaks when teams implement it badly
- Automation that helps instead of creating risk
- What works and what fails
- Metrics for peptide security operations in 2026
- Product fit: where ThreatCrush belongs
- Closing checklist for peptide security operations
Peptide security operations is a workflow problem, not a lab tool problem
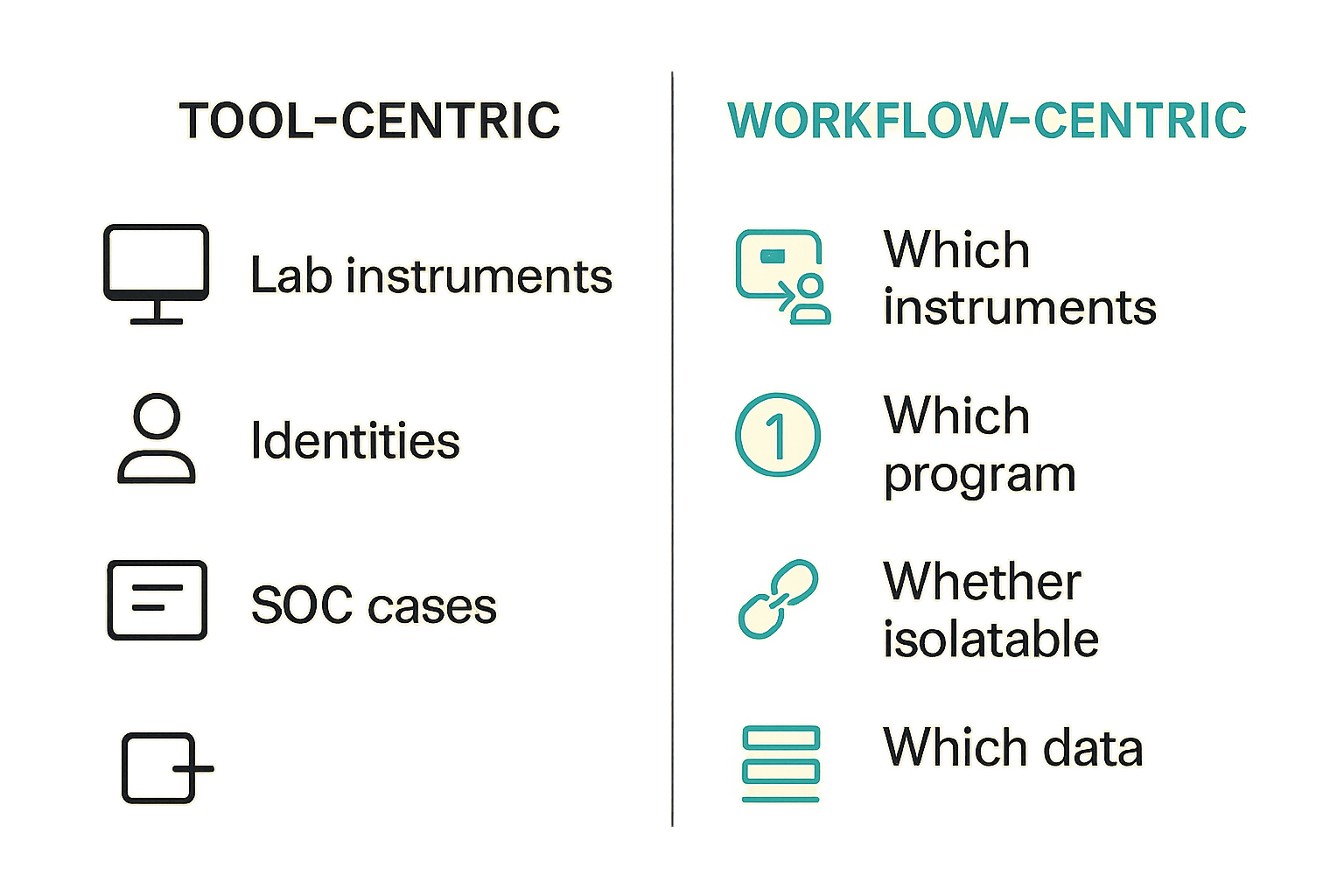
Lab systems create security context the SOC usually lacks
A peptide organization rarely fails because nobody bought security tools. It fails because the SOC sees a host, a username, and a destination IP, while the business sees a peptide library, an assay run, a synthesis queue, a batch record, or a partner transfer.
That gap matters. A generic endpoint alert on a lab workstation might be low severity in a normal office network. In a peptide environment, the same alert may touch an instrument controller, sequence design data, analytical results, or a shared directory used by a contract development and manufacturing partner.
The SOC needs context that normal asset inventories usually miss:
- Which instruments connect to the host.
- Which research program or manufacturing line depends on it.
- Whether the system can be isolated without corrupting a run.
- Whether the user is a scientist, engineer, service vendor, contractor, or automation account.
- Which data moved before and after the alert.
Practical rule: If the analyst cannot tell what scientific or manufacturing workflow an alert belongs to, the alert is not ready for reliable triage.
Why peptide environments are different from generic enterprise IT
Peptide work creates a messy security surface. You have research laptops, lab instruments, LIMS, ELN platforms, cloud modeling environments, file shares, identity providers, vendor remote access, quality systems, and sometimes manufacturing or OT networks.
The mistake teams make is treating this like a normal office estate with a few special machines. In practice, the special machines are where the operational risk lives. They may run old operating systems, fragile vendor software, local databases, weak authentication models, or network paths that were built for convenience rather than defense.
Peptide security operations must assume three things:
- Some systems cannot be patched quickly.
- Some systems cannot be interrupted casually.
- Some data is valuable before it ever becomes a commercial product.
Those assumptions change detection priorities. You are not only watching for malware execution. You are watching for unusual movement across research programs, suspicious access to sequence data, abnormal export of analytical results, misuse of service accounts, and unexpected remote access into lab or manufacturing networks.
What the SOC must own
The SOC does not need to become a peptide chemistry team. But it must own the security workflow around peptide operations.
That includes signal intake, enrichment, correlation, escalation, response coordination, evidence preservation, and post-incident validation. Lab owners, QA, manufacturing, legal, and IT may own parts of the environment. The SOC owns the decision process that turns weak signals into action.
A useful way to think about it is this: peptide security operations is the translation layer between technical telemetry and operational consequence.
Build the asset and data model before writing detections
Map identities, instruments, and compute
Detection engineering without an asset model becomes alert decoration. You add labels, tune severities, and still do not know what to do at 2 a.m.
Start with the operating map. For each major peptide workflow, identify:
- Human identities: scientists, automation engineers, QA reviewers, manufacturing operators, vendors.
- Non-human identities: service accounts, API tokens, instrument accounts, batch jobs.
- Instruments and controllers: synthesizers, HPLC systems, mass spectrometers, analyzers, robotics, storage appliances.
- Applications: ELN, LIMS, MES, QMS, modeling platforms, data lakes, file transfer tools.
- Compute zones: office, lab, cloud, manufacturing, partner access, backup.
The asset model should not be a static spreadsheet buried in a GRC folder. It should enrich alerts. If a host is part of an assay workflow, the analyst should see that in the case. If an account belongs to a vendor service contract, that should change the investigation path.
Classify peptide data by operational impact
Not all peptide data carries the same operational consequence. A public protocol PDF is not the same as a proprietary peptide sequence library, raw analytical output, toxicology result, manufacturing deviation record, or regulatory submission package.
Classify data by what happens if it is stolen, changed, deleted, or delayed. This tends to produce better SOC decisions than abstract labels such as confidential or restricted.
For example:
| Data type | Primary risk | SOC implication |
|---|---|---|
| Sequence libraries | IP theft and program compromise | Watch unusual access, bulk export, cross-program access |
| Raw instrument data | Integrity and reproducibility risk | Preserve evidence, verify chain of custody |
| Batch records | Quality and regulatory impact | Escalate to QA and manufacturing owners |
| Vendor transfer packages | Third-party exposure | Correlate identity, network, and file movement |
| Cloud modeling outputs | Competitive intelligence | Monitor API tokens, object storage, and downloads |
This is where experience from other state-heavy infrastructure is useful. The team at coinpayportal.com spends a lot of time thinking about checkout state, settlement, reconciliation, and custody boundaries; security teams in peptide environments face a similar pattern where the interface is not the system, the system is the state machine behind it.
Keep ownership visible
Asset ownership becomes critical during response. If an analyst has to ask five people who owns an instrument controller, the organization has already lost time.
Every high-value asset should have at least four ownership fields:
- Technical owner.
- Business or scientific owner.
- Response approver.
- Backup approver.
Practical rule: Do not onboard a critical lab or manufacturing asset into monitoring unless the SOC also knows who can approve isolation, credential reset, evidence collection, and downtime.
Reference architecture for peptide security operations
Control planes and telemetry sources
A workable architecture starts by separating control planes from telemetry. Control planes are where changes happen. Telemetry sources are where signals come from. Confusing the two leads to dangerous automation.
Core control planes usually include identity, endpoint, network access, cloud, email, remote access, vulnerability management, ticketing, and sometimes lab network segmentation. Telemetry sources include EDR events, identity logs, DNS, proxy, firewall, VPN, SaaS audit logs, cloud control plane logs, data access logs, instrument gateway logs, and backup events.
For peptide security operations, add workflow-aware telemetry where possible:
- LIMS and ELN audit events.
- File integrity monitoring for shared research repositories.
- Object storage access logs for modeling outputs.
- Remote vendor access logs.
- Instrument controller authentication and process execution events.
- Manufacturing or QA system access logs.
The architecture should not require every instrument to emit perfect logs. Many will not. Use network telemetry, identity context, jump hosts, and controlled file transfer paths to compensate.
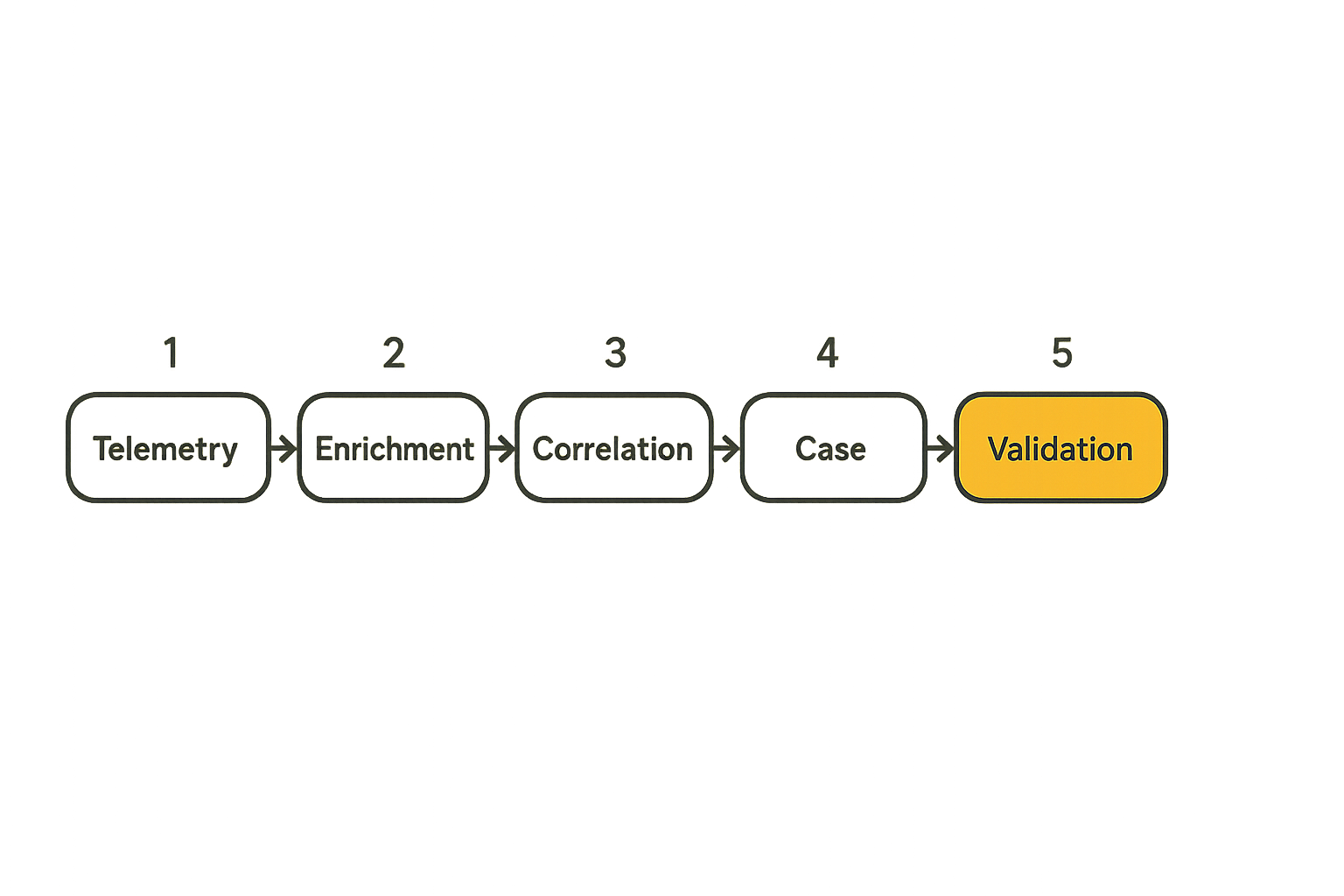
Event pipeline and enrichment
The pipeline should normalize events into a case-ready shape. Analysts need more than raw logs. They need event plus context.
A practical enrichment sequence looks like this:
- Ingest security and operational telemetry into the SIEM or detection pipeline.
- Normalize identity, host, IP, application, and data object fields.
- Enrich with asset criticality, workflow, owner, environment, and data class.
- Correlate across identity, endpoint, network, and data movement.
- Generate cases with recommended triage questions and response constraints.
The output should tell the analyst what changed, why it matters, who owns it, and what actions are safe.
A simple enrichment object might look like this:
asset_id: lab-hplc-ctl-014
workflow: peptide_quality_analysis
environment: lab_network
business_owner: qa-analytics
response_approver: qa-ops-manager
data_class: raw_analytical_results
containment_constraint: do_not_power_off_during_active_run
criticality: high
This kind of context is not glamorous. It is what keeps a SOC from turning every lab alert into a meeting.
Case management and response loops
The case is where architecture becomes operations. A good case record captures detection logic, supporting evidence, asset context, ownership, decisions, approvals, and containment outcome.
For peptide environments, case templates should include:
- Active run or batch status.
- Data integrity concern.
- Regulatory or QA notification requirement.
- Vendor involvement.
- Approved containment methods.
- Evidence preservation steps.
- Recovery validation owner.
What breaks in practice is the loop after the case closes. If response teams do not feed lessons back into asset records, detection logic, and playbooks, the same incident repeats with a new hostname.
Detection engineering for peptide environments
Start with behaviors that matter
Do not start by asking which vendor detections you can enable. Start with the behaviors that would hurt the organization.
For peptide security operations, high-value behaviors often include:
- Unusual access to sequence libraries or design repositories.
- Bulk download from ELN, LIMS, file shares, or object storage.
- Service account use outside expected hosts or schedules.
- Remote access into lab or manufacturing zones from unexpected geography or device posture.
- New process execution on instrument controllers.
- Credential reuse between office, lab, and cloud environments.
- Abnormal transfer to external partners or unmanaged destinations.
- Changes to analytical result files after acquisition.
Map each behavior to available telemetry. If you cannot detect it directly, identify compensating signals.
Turn lab context into detection logic
Generic detections become more useful when enriched with lab context. A login from a new device is interesting. A login from a new device into a LIMS account tied to a high-value program during an unusual time window is more important.
Example pseudo-logic:
select user, app, source_ip, asset_owner, data_class, count(*) as events
from access_events
where app in ('lims', 'eln', 'research_file_share')
and data_class in ('sequence_library', 'raw_analytical_results')
and user_risk != 'low'
and access_pattern = 'new_or_rare'
group by user, app, source_ip, asset_owner, data_class
The point is not the query syntax. The point is that detections should carry operational nouns: sequence library, raw result, assay workflow, vendor account, instrument controller.
Practical rule: A detection that cannot name the affected workflow will usually produce either noise or hesitation.
Validate with adversary and operator tests
Validation should test both attacker behavior and operator response. Many teams only test whether an alert fires. That is not enough.
A validation exercise should ask:
- Did the right signal fire?
- Did enrichment attach the correct owner and data class?
- Did the analyst know whether containment was safe?
- Did the escalation path work after hours?
- Did evidence collection preserve data integrity?
- Did recovery include workflow validation, not just host cleanup?
Run small tests. Simulate a rare download from a controlled repository. Test a vendor account login from an unexpected source. Generate a process execution event on a lab controller test box. Measure whether the SOC can reason about consequence, not just severity.
Workflow design from alert to containment
Triage should answer business questions
The first triage pass should answer four practical questions:
- What workflow is affected?
- What data or system state may have changed?
- Who can approve action?
- What response options are safe right now?
This prevents a common failure mode: analysts burn time proving that an alert is technically interesting while nobody determines whether a peptide synthesis run, QA review, or partner delivery is at risk.
A peptide security operations case should move quickly from signal to consequence. The SOC may not know the chemistry, but it can know the workflow and the decision tree.
Escalation paths need named owners
Escalation cannot depend on tribal knowledge. The SOC should have named owners for each critical workflow and a clear after-hours path.
Create escalation matrices for:
- Research data access incidents.
- Lab instrument compromise.
- Manufacturing system anomalies.
- Vendor remote access concerns.
- Cloud modeling environment compromise.
- Data integrity events.
Each matrix should include who decides, who executes, who communicates, and who validates recovery. These are different roles. Combining them under one vague owner creates delays and bad decisions.
Containment cannot break science blindly
In normal enterprise response, isolation is often a default action. In peptide environments, isolation may be correct, but it is not always safe.
Killing network access to an instrument controller may corrupt an acquisition. Disabling a service account may stop a scheduled transfer needed for QA review. Shutting down a server may damage evidence or interrupt a manufacturing process.
That does not mean the SOC should hesitate forever. It means containment options need to be pre-approved.
Examples:
- Block outbound internet but preserve local instrument communication.
- Disable interactive login while allowing a known service process.
- Move a host into a restricted VLAN after confirming run status.
- Snapshot cloud resources before revoking tokens.
- Require vendor access through a monitored jump path.
The mistake teams make is treating containment as a button. In this environment, containment is a decision tree.
What breaks when teams implement it badly
Noise from disconnected tools
Disconnected tools create duplicate alerts, missing context, and inconsistent severity. An EDR alert says suspicious script. The identity platform says impossible travel. The data tool says large download. The network tool says unusual destination. Nobody connects the events until hours later.
Noise is not just too many alerts. Noise is any signal that forces the analyst to reconstruct basic context manually.
Bad implementations usually have these traits:
- Asset inventory is not connected to alerts.
- Criticality labels are stale.
- Lab systems are grouped as generic workstations.
- Identity context does not distinguish vendor, scientist, operator, or service account.
- Cases do not capture response constraints.
The result is predictable: analysts either escalate everything or tune away the alerts that matter.
Blind spots around instruments and OT
Instrument controllers and OT-adjacent systems are often the weakest logging layer. Some run unsupported operating systems. Some cannot tolerate agents. Some are managed by vendors. Some sit behind informal network exceptions created years ago.
If the SOC waits for perfect endpoint telemetry, it will miss too much. Use compensating controls:
- Network segmentation with monitored choke points.
- Jump hosts for vendor access.
- DNS and proxy logging where endpoint logging is weak.
- File integrity monitoring on output directories.
- Strict identity paths for lab administration.
- Baselines for expected instrument communication.
The practical question is not whether every lab device can run modern security tooling. Many cannot. The question is whether activity around the device is observable enough to detect misuse and support response.
Unclear custody of evidence
Data integrity incidents require careful evidence handling. If raw analytical files may have changed, or batch records may have been accessed, the SOC needs a clean chain of custody.
What breaks in practice is uncontrolled collection. Someone copies files to a desktop. Someone opens the suspected record. Someone reboots the controller. Someone overwrites logs during troubleshooting.
Peptide security operations should define evidence handling before the incident:
- Who collects endpoint images or snapshots.
- Where evidence is stored.
- How hashes are recorded.
- Which systems require QA involvement.
- Which actions may alter regulated records.
A technically successful cleanup can still fail the business if evidence handling undermines confidence in the data.
Automation that helps instead of creating risk
Automate enrichment first
The safest early automation is enrichment. Pull owner, workflow, criticality, user type, data class, recent vulnerability exposure, known vendor relationship, and active maintenance window into the case.
This shortens investigation without changing system state. It also makes later automation safer because response decisions have better inputs.
Good enrichment automation answers:
- Is this asset part of a critical peptide workflow?
- Is the account human, service, vendor, or automation?
- Has this user accessed this data class before?
- Is the host in a lab, office, cloud, or manufacturing zone?
- Are there active runs, batches, or maintenance windows?
Use guardrails for response actions
Response automation should be constrained by asset type and workflow. A cloud workload can often be snapshotted and isolated differently from an instrument controller. A vendor account can be disabled differently from a service account tied to a validated process.
Use approval gates for high-consequence actions:
- Isolate lab controller.
- Disable service account.
- Delete or quarantine files in regulated repositories.
- Revoke production API tokens.
- Block partner transfer path.
Low-risk actions can be automated more aggressively:
- Add case enrichment.
- Request owner confirmation.
- Pull recent login history.
- Capture volatile metadata.
- Open a QA notification task.
Practical rule: Automate actions that improve decision quality before automating actions that change production, lab, or manufacturing state.
Make idempotency and rollback explicit
Security automation needs the same discipline as production engineering. Actions should be repeatable, auditable, and reversible where possible.
If a playbook disables an account, it should check current state first and record the prior state. If it changes network access, it should record the rule, scope, requester, approver, and rollback path. If it snapshots a cloud resource, it should tag the snapshot with the case ID and retention policy.
A lightweight response action record can prevent confusion:
action: restrict_vendor_vpn
case_id: soc-2026-0518-042
requested_by: soc-analyst-2
approved_by: lab-ops-owner
scope: vendor_account_group_peptide_lab
previous_state: full_vpn_access
new_state: jump_host_only
rollback_owner: network-security
expires: 2026-05-27T18:00:00Z
Without this, response automation becomes another source of operational risk.
What works and what fails
What works in production
The strongest programs are boring in the right places. They have clean asset context, stable escalation paths, tested playbooks, and detection logic tied to real workflows.
What works:
- Start with the top peptide workflows, not the entire enterprise.
- Build asset context into cases before adding more alerts.
- Treat vendor access as a first-class detection and response path.
- Monitor data movement around sequence libraries, raw results, and batch records.
- Use tabletop exercises to test containment constraints.
- Review closed cases for missing context and broken ownership.
These practices are not exciting, but they reduce investigation time and improve decisions.
What fails under pressure
What fails:
- Buying another tool to compensate for weak ownership.
- Writing detections without knowing who can approve action.
- Treating lab controllers like normal laptops.
- Ignoring cloud object storage because the SIEM already has endpoint logs.
- Letting vendor access bypass normal identity and monitoring paths.
- Closing incidents after host cleanup without validating workflow integrity.
Under pressure, teams fall back to what is documented. If the documented process is vague, the response will be vague.
Comparison table for common choices
| Decision area | What works | What fails |
|---|---|---|
| Asset model | Workflow, owner, criticality, containment constraints | Hostname and IP only |
| Detection strategy | Behavior tied to peptide data and lab operations | Generic alerts with no business context |
| Vendor access | Monitored jump path and named sponsor | Shared credentials and broad VPN |
| Automation | Enrichment, evidence capture, approval gates | Blind isolation and account disablement |
| Incident closure | Recovery plus workflow validation | Ticket closed after malware removal |
| Metrics | Time to decision and coverage by workflow | Alert volume and dashboard screenshots |
The pattern is simple. Programs fail when they optimize for tool activity. They improve when they optimize for decision quality.
Metrics for peptide security operations in 2026
Measure time and decision quality
Mean time to detect and respond still matters, but peptide security operations needs more specific metrics.
Useful metrics include:
- Time from alert to workflow identification.
- Time from alert to owner engagement.
- Time from alert to safe containment decision.
- Percentage of high-severity cases with complete asset context.
- Percentage of critical workflows with tested playbooks.
- Number of incidents requiring manual owner discovery.
These metrics expose workflow friction. If the SOC detects quickly but spends hours finding an owner, the program is not mature.
Track coverage by workflow
Coverage should be measured by workflow, not only by log source. A dashboard that says EDR coverage is 96 percent may hide the fact that key instrument controllers have no direct telemetry and vendor access is poorly monitored.
Track coverage for each critical peptide workflow:
- Identity visibility.
- Endpoint or compensating telemetry.
- Network visibility.
- Data access logging.
- Detection logic.
- Response playbook.
- Named owner.
- Last validation date.
This creates an honest view of operational readiness.
Review exceptions like incidents
Exceptions are risk decisions. Treat them that way.
If a lab system cannot run EDR, document the compensating telemetry. If a vendor needs remote access, define scope and expiry. If a service account cannot rotate credentials on the normal schedule, record the reason and review date.
Many teams allow exceptions to become permanent architecture. That is how blind spots become normal.
Product fit: where ThreatCrush belongs
Connect proactive and reactive work
ThreatCrush fits best when peptide security operations is treated as a continuous loop, not a pile of alerts. The same asset and exposure context that helps proactive security should inform triage and response.
For example, if a vulnerable lab host is tied to a high-value workflow and then generates unusual outbound traffic, that case should not look the same as a generic endpoint alert. Exposure, asset criticality, threat intelligence, and workflow context should converge.
That is the useful product fit: reducing the distance between what the organization already knows and what the analyst needs during an investigation.
Keep integrations boring
Security operations tools should integrate with the systems teams already use: SIEM, EDR, identity, vulnerability management, ticketing, cloud logs, and case management. Boring integrations are good. They reduce manual copying, missing fields, and analyst guesswork.
For peptide environments, the integration priority should be context flow:
- Asset and owner context into alerts.
- Exposure and vulnerability context into cases.
- Case outcomes back into detection tuning.
- Response constraints into playbooks.
- Validation results back into coverage reporting.
A platform does not need to replace every tool. It needs to make the workflow coherent.
Use the platform where it reduces toil
The right question is not whether a platform can do everything. The right question is where it reduces toil without hiding risk.
ThreatCrush is useful where teams need to connect signals, prioritize operationally meaningful risk, and shorten investigation loops. That is especially relevant in peptide security operations because context is scattered across lab owners, IT systems, cloud platforms, and security tools.
Use product capabilities to make analysts faster, but keep response ownership explicit. Tools can recommend, enrich, correlate, and orchestrate. The organization still needs clear authority for actions that affect science, QA, or manufacturing.
Closing checklist for peptide security operations
Questions to ask this quarter
If you are building or improving peptide security operations in 2026, start with practical questions:
- Which peptide workflows would create the most damage if disrupted, altered, or exposed?
- Can the SOC identify those workflows from an alert without asking around?
- Are critical assets enriched with owner, data class, and containment constraints?
- Are vendor access paths monitored and tied to named sponsors?
- Do detections cover data movement, identity misuse, lab systems, and cloud modeling environments?
- Are response actions pre-approved for high-consequence systems?
- Do closed incidents feed back into asset records, detections, and playbooks?
- Are exceptions reviewed as risk decisions rather than forgotten tickets?
If the answer is no to several of these, more alert volume will not fix the program.
The operating principle
Peptide security operations works when the SOC can connect signal to workflow, workflow to owner, owner to decision, and decision to safe response.
That is the architecture. Everything else is implementation detail.
The closing point is simple: peptide security operations should not be built around tool coverage alone. Build it around decision quality, data integrity, and response paths that respect how peptide research and manufacturing actually run.
Try threatcrush.com
ThreatCrush helps security teams connect signals, operational context, and response workflows for modern SOC programs, including peptide security operations. Try threatcrush.com.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →