Freelancing Threat Detection: How SOC Teams Can Use External Detection Talent Without Creating More Noise

Freelancing threat detection sounds simple until the first external engineer ships a rule nobody owns, tuned against logs nobody trusts, for an alert queue nobody has time to monitor.
Many SOC leaders do not reach for freelancers because they want a new operating model. They do it because the backlog is ugly: cloud detections that never shipped, noisy endpoint rules, stale Sigma content, half-finished ATT&CK mapping, and detection gaps found during the last incident review.
Teams think the problem is finding a sharp detection engineer for a few weeks. The real problem is designing a workflow where external detection work improves the SOC without adding fragile alerts, unclear access, or tribal knowledge.
That changes the conversation. Freelancing threat detection is not a staffing shortcut. It is an architecture decision across identity, telemetry, rule lifecycle, validation, handoff, and response ownership.
Table of contents
- Why freelancing threat detection is an operating model
- What freelancing threat detection should and should not cover
- Design the engagement around signals, not tickets
- Build an access model that assumes turnover
- The practical workflow for freelance detection engineering
- Tooling and collaboration patterns that work
- What breaks when teams implement it badly
- Measuring freelance detection work without vanity metrics
- How SOC leaders should buy freelance detection capacity
- Where ThreatCrush fits in a freelance threat detection program
Why freelancing threat detection is an operating model
The hiring problem is not only headcount
Detection engineering is one of those security functions where backlog hides inside every tool. The SIEM has rules that need tuning. The EDR has detections nobody reviewed after the last agent upgrade. Cloud logs are available but underused. Identity events are collected but not correlated with endpoint behavior. Threat intelligence arrives, but only some of it becomes useful detection logic.
A full-time hire may be the right long-term answer. But full-time hiring is slow, and many detection needs are not continuous at the same intensity. You may need four weeks of concentrated cloud detection work, two weeks of log source normalization, or a short burst of adversary emulation support before a purple team exercise.
The mistake teams make is treating a freelancer as a temporary analyst who can be dropped into the queue. That usually disappoints both sides. A freelance detection engineer creates the most value when the work is scoped as engineering output with clear acceptance criteria.
The work is bursty by nature
Threat detection has seasonal spikes. New SaaS platforms get deployed. A merger brings new telemetry. A regulator asks for proof of monitoring. A breach at a peer company causes leadership to ask whether similar behavior would be caught internally. None of those events wait for annual planning.
Freelancing threat detection fits this bursty pattern when the SOC can package work into bounded problems: detect suspicious OAuth grant activity, reduce noisy PowerShell alerts, map cloud detections to specific response runbooks, or validate ransomware precursor coverage.
That does not mean every SOC should outsource core detection strategy. It means external contributors can be useful if the internal team controls priorities, production approval, and response ownership.
Architecture beats heroics
A useful way to think about it is this: a freelancer should not be the only person who understands why a detection exists. If that happens, the SOC bought a dependency, not capacity.
Good freelance detection work leaves behind artifacts the team can operate: rule logic, test cases, tuning notes, known limitations, required fields, example events, runbook links, and owner metadata. The person may leave after the engagement. The detection should not.
Practical rule: If a detection cannot be reviewed, tested, tuned, and retired by the internal SOC after the freelancer leaves, it is not finished.
What freelancing threat detection should and should not cover
Good candidate work for freelancers
Freelancers are often effective on work that is well-bounded, technically deep, and painful for the internal team to prioritize. Examples include:
- Writing detections for a new telemetry source such as cloud audit logs, identity provider events, DNS, or SaaS admin activity.
- Converting threat intelligence into detection logic with documented assumptions.
- Translating Sigma, YARA-L, KQL, SPL, SQL, or vendor-specific logic into the environment's actual schema.
- Tuning noisy detections by reviewing event samples and analyst feedback.
- Building detection test cases using atomic tests, replayed logs, or controlled simulations.
- Creating coverage maps for specific attack paths, not generic technique catalogs.
- Reviewing existing detections for broken fields, stale exceptions, or missing response context.
The practical question is whether the work can be scoped, reviewed, and accepted without making the freelancer a permanent part of the SOC chain of command.
Work that needs tighter ownership
Some work should stay close to employees or long-term trusted partners. This includes production incident command, sensitive executive investigations, legal-hold collection decisions, insider threat cases, and detections involving highly restricted data.
Freelancers can support parts of these workflows, but the accountable owner should be internal. The boundary matters. If an external contributor has authority to change live detections during an active incident without review, the SOC has created a governance problem.
This is not about distrust. It is about blast radius. Temporary contributors should be able to improve detection coverage without becoming an uncontrolled path into the production security stack.
A useful comparison
| Delivery model | Best use | What works | What fails |
|---|---|---|---|
| Internal detection team | Core strategy, ownership, production decisions | Deep business context and long-term accountability | Backlog grows when capacity is fixed |
| Freelance detection engineer | Bounded projects, tuning sprints, specialized rule work | Fast access to focused expertise | Poor handoff creates orphaned detections |
| MSSP or MDR provider | Continuous monitoring, triage, external coverage | Operational coverage and predictable service | Generic detections may not match internal risk |
| Consulting firm | Assessments, program design, major transformations | Structured delivery and broad expertise | Can be too heavy for small detection changes |
The point is not that one model wins. The point is matching the model to the control you need. Freelancing threat detection works best as a capacity layer around an internal detection lifecycle, not as a replacement for one.
Design the engagement around signals, not tickets
Start with detection outcomes
If the statement of work says only build detections for cloud attacks, expect vague output. If it says detect impossible travel followed by privileged role assignment in Entra ID with a runbook and sample events, the work becomes testable.
Start with outcomes like:
- Detect misuse of privileged cloud roles after suspicious authentication.
- Identify lateral movement indicators across endpoint and identity telemetry.
- Reduce analyst time spent on known benign administrative scripts.
- Add coverage for initial access techniques relevant to the company's exposed services.
- Validate whether existing ransomware precursor detections still fire after recent log pipeline changes.
The outcome should connect to an analyst decision. What should the SOC do if this fires? Escalate? Suppress? Enrich? Open an incident? Request endpoint isolation? If nobody can answer, the detection is not ready.
Define signal quality before work begins
Signal quality is not the same as clever logic. A detection can look elegant and still be useless if it fires on normal admin behavior every morning.
Define quality in operational terms:
- Required fields are present and normalized.
- Alert text explains the suspicious behavior.
- Severity matches the response expectation.
- Known benign patterns are documented, not hidden in someone's memory.
- The rule has at least one test method.
- The runbook tells a tier-one analyst what to check first.
Practical rule: Do not pay for rule count. Pay for usable signals with evidence, context, and a clear next action.
This is where many freelance engagements go sideways. The buyer asks for twenty detections. The freelancer ships twenty queries. The SOC receives twenty new ways to increase alert volume. That is not detection engineering. That is content dumping.
Keep the analyst loop explicit
Analysts know where detections fail because they live with the noise. Build a feedback loop into the engagement. A freelancer should review at least a sample of analyst dispositions, false-positive reasons, and escalation notes before tuning existing rules.
A simple loop works:
- Detection engineer proposes or modifies logic.
- SOC runs it in shadow mode or low-severity mode.
- Analysts tag outcomes using a small set of reasons.
- Detection engineer tunes against observed behavior.
- SOC owner approves production behavior.
That changes the conversation from did the freelancer write the query to did the detection improve the queue.
Build an access model that assumes turnover
Least privilege is a delivery requirement
External detection engineers need enough access to understand telemetry, but they do not need unlimited access to everything. Least privilege is not an administrative detail. It determines whether freelancing threat detection can scale safely.
Common access patterns include read-only SIEM access, limited search windows, anonymized exports, development workspaces, Git repository access, and ticket access scoped to relevant detection tasks. In some cases, the freelancer may not need direct production SIEM access at all if the internal team can provide representative event samples.
The mistake teams make is granting broad access because setup is inconvenient. That may save a day at the beginning and create a painful audit problem later.
Set data boundaries early
Detection work can expose sensitive information: usernames, hostnames, internal IPs, file paths, SaaS content metadata, email subjects, process command lines, and investigation notes. Decide what can be shared before the engagement starts.
A practical boundary model includes:
- Which systems the freelancer can access directly.
- Which logs can be exported.
- Whether personal data must be redacted.
- Whether screenshots are allowed.
- Where working notes may be stored.
- Whether AI-assisted tooling can be used on customer data.
- How sample events should be handled after the project.
For many teams, the AI question is now unavoidable. A contractor using an external assistant to debug query logic is different from pasting raw security logs into an unmanaged service. Write the rule down.
Offboarding is part of the contract
Offboarding should be boring. If it is dramatic, the access model was wrong.
At the end of the engagement, remove accounts, rotate shared credentials if any were mistakenly used, transfer repository ownership, close temporary access groups, archive deliverables, and confirm deletion or return of exported data. Make this checklist part of acceptance, not an afterthought.
Practical rule: A freelance detection engagement is not complete until access is revoked and the SOC can operate the delivered detections without the freelancer.
The practical workflow for freelance detection engineering
Intake and scoping
Good outcomes start with tight intake. The SOC owner should provide the problem, the telemetry available, the expected response, and the acceptance criteria. The freelancer should push back on vague objectives.
A strong intake packet includes:
- Business or threat driver for the work.
- Relevant log sources and retention windows.
- Current detection coverage and known gaps.
- Example benign and suspicious events, if available.
- Required query language or detection format.
- Review process and production approval owner.
- Definition of done.
The definition of done should be explicit. For example: detection logic merged to repository, validated against three sample events, deployed in monitor mode for five business days, false positives documented, runbook attached, owner assigned.
Build, test, and tune
A practical implementation sequence looks like this:
- Confirm telemetry fields and normalization. Do not assume the schema matches vendor documentation.
- Draft detection logic in a development branch or non-production workspace.
- Attach sample events and explain why the behavior is suspicious.
- Run historical searches to estimate volume and identify obvious benign patterns.
- Deploy in monitor, shadow, or low-severity mode before paging anyone.
- Collect analyst feedback and disposition data.
- Tune exceptions with reason codes and review dates.
- Promote to production only after the SOC owner accepts the detection.
What breaks in practice is skipping step one. If fields are missing, renamed, delayed, or inconsistently parsed, the best detection logic will behave badly. Freelancers should be encouraged to report telemetry problems rather than pretending every issue can be solved in query syntax.
Handoff and acceptance
Handoff is where freelance work becomes SOC capability. It should include more than a merged rule.
For each delivered detection, require:
- Purpose and threat behavior.
- Data sources and required fields.
- Query or rule logic.
- Test method and sample events.
- Expected alert volume or volume notes.
- Known false positives.
- Tuning guidance.
- Severity rationale.
- Runbook link or analyst steps.
- Owner and review date.
Acceptance should be performed by the internal detection owner, not only the project manager. If the SOC cannot explain the detection, it should not be promoted.
Tooling and collaboration patterns that work
Use shared repositories for detection logic
Detections should live in version control whenever possible. That does not mean every SIEM makes this easy. It does mean the source of truth should not be a freelancer's local folder or a private document.
A simple repository structure can be enough:
/detections
/cloud
/identity
/endpoint
/tests
/sample-events
/runbooks
/triage-guides
/docs
detection-standards.md
field-mapping.md
Use pull requests for review. Require comments for assumptions. Track exceptions as code or structured configuration. The goal is not ceremony. The goal is to make detection changes reviewable and reversible.
Separate SIEM access from production authority
A freelancer may need to search logs and draft content. That does not mean they should be able to enable high-severity production alerts without approval.
A safer pattern is:
- Read access to relevant telemetry.
- Write access to development detections or branches.
- Pull request review by internal detection owner.
- Controlled deployment by SOC engineering or platform owner.
- Post-deployment monitoring with rollback criteria.
This separation protects the SOC and the freelancer. Nobody wants a contractor blamed for a production paging storm caused by an unclear approval process.
Set a communication cadence
Freelance work fails when the contributor disappears into a cave and returns with a pile of queries. Detection engineering needs iteration because the environment always has surprises.
Use a lightweight cadence:
- Kickoff to confirm scope and access.
- Twice-weekly working sync during active build phases.
- Async notes for blockers, assumptions, and sample findings.
- End-of-week summary of shipped, blocked, and risky items.
- Final handoff and review session.
Keep meetings short, but do not eliminate them. Security context is expensive to rediscover.
What breaks when teams implement it badly
Unowned detections decay
Every detection has a half-life. Cloud providers change event names. Endpoint tools change schemas. Admin behavior changes. Business applications move. Exceptions accumulate.
If a freelancer ships detections without an internal owner, those detections become abandoned infrastructure. They may still fire, but nobody knows whether they should. Eventually analysts learn to ignore them.
Ownership metadata should be mandatory: owner, backup owner, review date, related service, and escalation path. If the owner changes teams, the detection should be reassigned like any other operational asset.
Context loss creates bad alerts
Freelancers are often strong technically, but they start with less business context. They may not know that a service account runs unusual commands during backup windows, that developers use a particular remote access tool legitimately, or that a region has a different identity pattern.
The SOC has to provide context intentionally. Give the freelancer access to approved admin patterns, critical asset lists, known noisy services, and prior incident lessons where appropriate. Without that, they will either overfit to generic attacker behavior or suppress too much.
The mistake teams make is expecting the external engineer to infer business context from logs alone. Logs show behavior. They do not always show intent.
False positives scale faster than value
A single noisy detection can consume more analyst time than the project saved. Ten noisy detections can poison trust in the whole engagement.
False positives are not just a tuning issue. They are a product quality issue for the SOC. If analysts cannot trust a new signal, they route around it mentally. Once that happens, even the true positives suffer.
What works is staged deployment, analyst feedback, and measurable acceptance. What fails is enabling everything at high severity because the project deadline arrived.
Measuring freelance detection work without vanity metrics
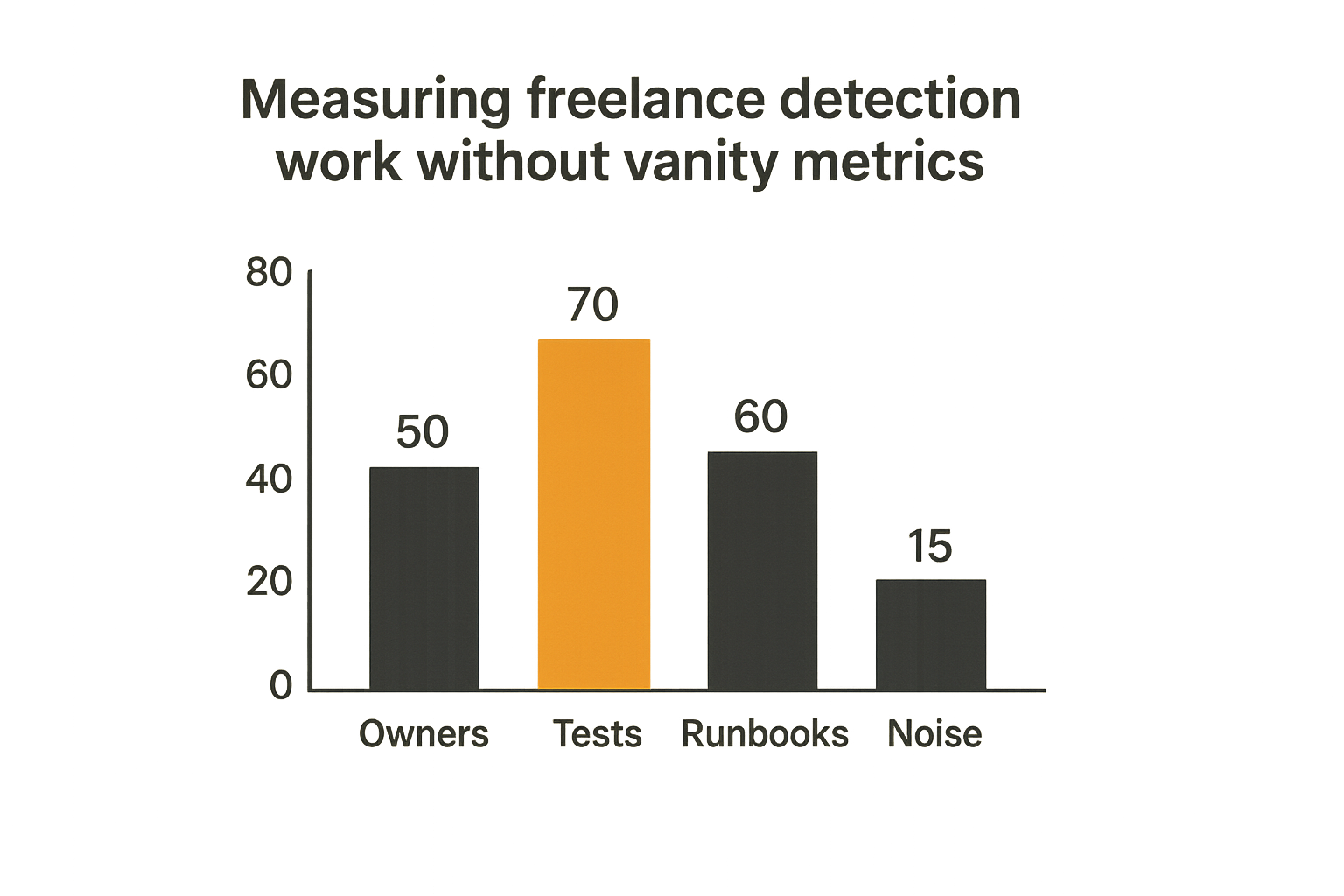
Operational metrics
Rule count is the easiest metric and one of the least useful. It tells you activity happened. It does not tell you whether the SOC improved.
Better operational metrics include:
- Percent of delivered detections with assigned owners.
- Percent with test cases or sample events.
- Percent with runbooks or triage notes.
- Alert volume during monitor mode.
- False-positive reasons by category.
- Time from draft to accepted production deployment.
- Number of detections retired or consolidated.
These metrics are not glamorous, but they reveal whether the work entered the detection lifecycle instead of becoming shelfware.
Validation metrics
Validation asks a harder question: would this detection catch the behavior we care about?
Use controlled tests where possible. That might include atomic tests, purple team activity, replayed logs, lab-generated events, or known historical incidents. The right method depends on the telemetry and risk. The key is that validation should be documented.
A detection with no test path is not automatically bad. Some behaviors are difficult to reproduce safely. But the limitation should be stated. The SOC should know whether a rule was validated by live testing, historical evidence, synthetic logs, or logic review only.
Business metrics
Security teams still need to explain why the spend mattered. Business metrics connect freelance detection work to operational risk reduction.
Examples include:
- Coverage added for a specific high-risk platform.
- Reduction in recurring analyst noise from a known alert family.
- Faster triage because alerts now include better context.
- Closed gaps from incident postmortems or control assessments.
- Improved readiness for a planned cloud migration or product launch.
Do not overclaim. Freelancing threat detection does not magically prevent incidents. It can, however, improve the probability that relevant behavior is seen, understood, and acted on before damage expands.
How SOC leaders should buy freelance detection capacity
Use a retainer and project hybrid
Pure hourly work can drift. Pure fixed-scope work can become brittle when telemetry surprises appear. A hybrid model often works better: a defined project backlog with a small retainer for iteration, tuning, and follow-up.
For example, a SOC might contract for a six-week identity detection sprint, then retain a small number of hours the following month to tune based on analyst feedback. That keeps incentives aligned with maintainability instead of one-time delivery.
The team at ugig.net has seen the same pattern across freelance-heavy work: the best engagements define the deliverable, the review loop, and the operating boundary before the first task starts.
Vet for workflow judgment, not only query syntax
A strong freelancer can write SPL, KQL, SQL, Sigma, or vendor-specific detections. A stronger one asks uncomfortable questions before writing anything.
Look for signs of workflow judgment:
- They ask who owns production approval.
- They ask how false positives are dispositioned.
- They ask which fields are reliable.
- They ask how severity maps to response.
- They ask whether test data exists.
- They ask what should happen after the alert fires.
Query syntax is necessary. Operational judgment is what prevents the syntax from becoming noise.
Align pricing with maintainable outcomes
Avoid buying detections by the dozen. It encourages shallow output and discourages tuning. Better pricing models tie delivery to accepted artifacts: validated detection logic, documentation, runbook, test evidence, and handoff.
For small teams, start with a pilot. Pick one detection family or one telemetry source. Measure the workflow. If access, review, and handoff are painful in a small pilot, they will be worse in a larger engagement.
A good pilot might be narrow: reduce noise in three endpoint detections, add identity detections for privileged role changes, or create cloud storage exfiltration monitoring. The pilot should prove the operating model, not just the freelancer's technical ability.
Where ThreatCrush fits in a freelance threat detection program
Connect proactive and reactive work
Freelance detection work sits between proactive security and reactive operations. A gap found in threat modeling should become detection logic. A lesson from incident response should become a better signal. A noisy alert should feed back into engineering, not remain an analyst tax.
ThreatCrush is built for security operations teams trying to connect those pieces: signals, workflows, detection context, ownership, and response. In a freelance model, that connective tissue matters even more because contributors may change while the SOC mission does not.
The product-fit question is not whether a platform can manage freelancers. The better question is whether your SOC has a place where detection work is tied to operational context and action. If that context lives across chats, spreadsheets, SIEM comments, and contractor notebooks, handoff will be fragile.
Give contributors operational context
External detection talent needs enough context to be useful without being granted uncontrolled authority. A good platform layer helps by making ownership, signal status, response notes, and detection workflow visible.
That is the practical middle ground. Freelancers can help build and tune detection capability. Internal teams retain prioritization, approval, and response accountability. The SOC gets capacity without turning every short-term engagement into a long-term dependency.
Freelancing threat detection works when the system is designed for it: clear intake, bounded access, reviewable logic, validation evidence, analyst feedback, and durable ownership. Skip those pieces and the SOC just buys more alerts.
Try threatcrush.com
ThreatCrush helps security operations teams connect detection signals, workflows, and response context so external and internal contributors can ship work the SOC can actually operate. Try threatcrush.com.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →