Cybersecurity Jobs in 2026: A SOC Operator’s Guide to Roles, Skills, and Workflow Ownership

Cybersecurity jobs look simple from the outside. Analyst, engineer, architect, responder, threat hunter, manager. Pick a title, match some tools, apply or hire.
Then production reality shows up. Alerts do not respect job descriptions. Incidents cross team boundaries. Detection gaps hide inside logging decisions. Threat intelligence gets collected but never used. The same person who is supposed to tune SIEM rules is also writing an executive incident summary at 2 a.m.
Teams think the problem is finding enough cybersecurity jobs or enough cybersecurity talent. The real problem is that many roles are described as tool ownership when the work is actually workflow ownership.
That changes the conversation. If you are building a SOC career, you need to understand which operating loop you want to own. If you are hiring, you need to define the decisions, handoffs, evidence, and outcomes the role is responsible for. A title is not an architecture.
Table of contents
- Cybersecurity jobs are workflow ownership roles
- Map cybersecurity jobs to SOC operating loops
- The cybersecurity jobs matrix for security operations
- What breaks when teams hire for tools instead of outcomes
- Skills that compound across cybersecurity jobs
- A practical workflow for choosing your next cybersecurity job
- Hiring cybersecurity jobs as a manager or architect
- What works in production SOC teams
- What fails in production SOC teams
- How AI and automation change cybersecurity jobs
- Where ThreatCrush fits
Cybersecurity jobs are workflow ownership roles
The mistake teams make is treating cybersecurity jobs like static seats on an org chart. In a working SOC, the job is rarely static. A detection engineer may need to understand endpoint telemetry, cloud control planes, attacker tradecraft, and change management. An incident responder may need to know legal escalation paths and how to preserve evidence. A SOC architect may need to decide what not to collect because collection without use just creates cost.
A useful way to think about it is this: every security role owns part of the loop from signal to decision.
Signal appears. Someone decides whether it matters. Someone enriches it. Someone contains the risk. Someone validates the detection. Someone fixes the control gap. The job title matters less than whether that loop works under pressure.
The role name is less important than the handoff
Most SOC failures are handoff failures. The alert moves from tier one to tier two with no context. The incident responder closes the case but the detection engineer never sees the missed signal. Threat intelligence identifies an active actor but no one maps it to exposed assets. Vulnerability management publishes a priority list that the SOC cannot use in triage.
Good cybersecurity jobs are designed around clean handoffs:
- What evidence must be attached before escalation?
- What decision must be made before a ticket changes state?
- Who owns validation after containment?
- What gets fed back into detection engineering?
- What gets documented for the next shift?
Practical rule: if a role cannot name its upstream inputs and downstream consumers, it is not a role yet. It is a bucket of tasks.
Why job postings feel noisy in 2026
Many job postings ask for everything because the hiring team has not separated workflows. The same posting may ask for SIEM administration, malware analysis, cloud incident response, threat hunting, Python automation, compliance evidence, and executive reporting. That is not one job. That is an unresolved operating model.
For candidates, noisy postings are not automatically bad. Smaller teams need range. The practical question is whether the organization understands the tradeoff. A broad role can be excellent if it comes with decision authority and engineering time. It becomes a trap when it is just an overloaded queue with no ownership.
For managers, noisy postings attract mismatched candidates. You get tool keywords instead of operational judgment. The resume may look good, but the person cannot tell you how to reduce duplicate alerts, when to suppress a detection, or how to prove containment.
The hiring signal that actually matters
The strongest signal is not a certificate list or a vendor tool list. It is whether the person can reason through a messy security workflow.
Ask them to explain how an alert becomes an incident. Ask what evidence they would want before isolating a host. Ask how they would tune a detection without hiding attacker behavior. Ask how they would know whether a threat intelligence feed made the SOC faster or just louder.
Good operators can explain constraints. Great operators can explain tradeoffs.
Map cybersecurity jobs to SOC operating loops
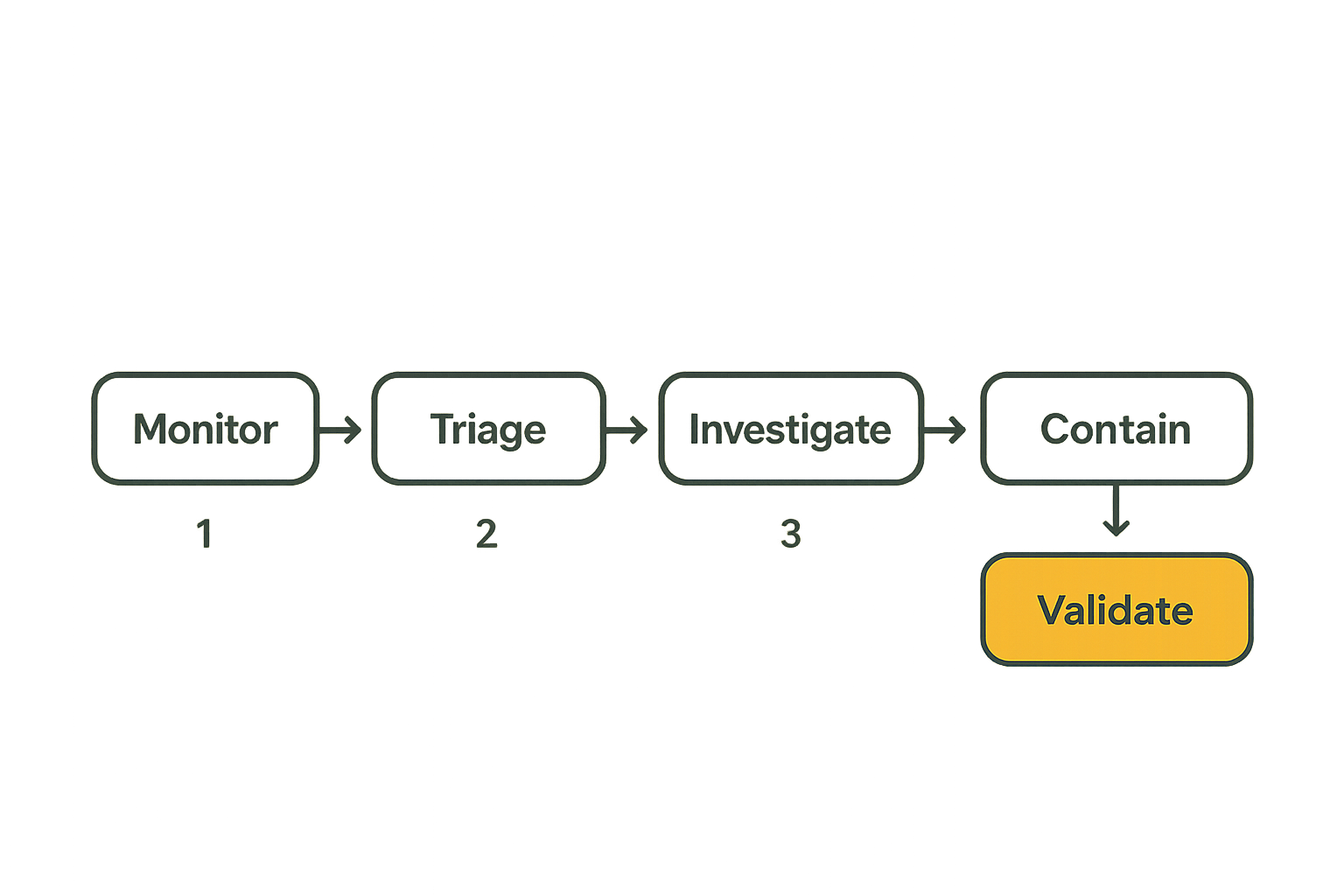
Cybersecurity jobs make more sense when mapped to operating loops instead of titles. Security operations is not a single queue. It is a set of loops that run at different speeds: real-time triage, active investigation, containment, detection improvement, threat intelligence activation, exposure reduction, and post-incident learning.
For a broader baseline on how those loops fit into a modern SOC, the ThreatCrush guide to security operations in 2026 is useful background before you map individual roles.
Monitor and triage
This loop is about signal intake and initial decision quality. The work includes alert review, deduplication, enrichment, severity adjustment, escalation, and false-positive handling.
Typical roles:
- SOC analyst
- MDR analyst
- Security monitoring engineer
- Detection triage specialist
What breaks in practice is that triage is treated as low-skill clicking. It is not. Triage is where the SOC spends its attention budget. Bad triage either escalates noise or misses attacker behavior. Both are expensive.
A strong triage operator knows the environment, understands normal behavior, reads raw evidence, and can separate weird from dangerous. They also know when not to over-investigate.
Investigate and contain
This loop starts when the signal is credible enough to require deeper investigation. It includes scoping, timeline building, host and identity analysis, containment decisions, communication, evidence preservation, and recovery coordination.
Typical roles:
- Incident responder
- Digital forensics analyst
- Tier two or tier three SOC analyst
- Cloud security responder
- Identity threat responder
The practical question is not whether the person knows a forensic tool. The practical question is whether they can make defensible decisions while the environment is changing.
Containment is full of tradeoffs. Disable an account too early and you may disrupt business. Wait too long and the attacker expands access. Isolate a server without understanding dependencies and you create a second incident. The best responders are disciplined under uncertainty.
Engineer and validate
This loop improves the system. It includes detection engineering, log source onboarding, parser quality, correlation logic, test cases, automation, adversary emulation, and post-incident control improvements.
Typical roles:
- Detection engineer
- SIEM engineer
- Security automation engineer
- SOC platform engineer
- Security architect
Engineering roles are where cybersecurity jobs become architecture jobs. You are deciding what the SOC can see, what it can trust, and how fast it can act.
Practical rule: detection engineering is not writing rules. Detection engineering is maintaining a production signal system with tests, owners, failure handling, and feedback loops.
The cybersecurity jobs matrix for security operations
The job market uses titles inconsistently, so a matrix is more useful than a title glossary. The goal is to understand the operating ownership behind the label.
Core SOC roles and what they own
| Role | Primary ownership | Strong signal in candidates | Common failure mode |
|---|---|---|---|
| SOC analyst | Triage, escalation, evidence capture | Explains why an alert matters or does not | Measures work by ticket volume only |
| Incident responder | Scoping, containment, recovery coordination | Builds timelines and preserves evidence | Jumps to action without validating blast radius |
| Detection engineer | Detection logic, telemetry quality, tests | Writes hypotheses and validates coverage | Ships rules with no feedback loop |
| Threat hunter | Hypothesis-driven investigation | Turns uncertainty into testable questions | Produces interesting findings no one operationalizes |
| Threat intelligence analyst | Actor, campaign, and indicator context | Converts intelligence into SOC action | Collects feeds that increase noise |
| SOC architect | Platform, integration, and operating model | Designs handoffs and failure handling | Optimizes tools while ignoring workflow |
| Security automation engineer | Repeatable enrichment and response actions | Adds guardrails, idempotency, and rollback | Automates broken processes |
This table is not a hierarchy. It is a map of ownership. Many people will cover multiple rows, especially in smaller teams. The important part is naming which hat is being worn when a decision is made.
Adjacent roles that shape the SOC
Some cybersecurity jobs sit outside the SOC but heavily affect SOC performance:
- Cloud security engineers decide what cloud activity is visible.
- IAM engineers shape identity evidence and containment options.
- Vulnerability managers influence prioritization during active exploitation.
- GRC teams define reporting obligations and evidence requirements.
- Security product managers coordinate roadmaps for internal capabilities.
Related reading from our network: teams treating SOC work as an internal product may find security operations product management useful because many hiring problems are really roadmap and ownership problems.
The mistake teams make is isolating these functions. A SOC cannot respond well to cloud attacks if cloud logging is owned elsewhere with no shared runbook. An incident responder cannot prove containment if IAM has no rapid process for token revocation or session invalidation.
How seniority changes the work
Junior roles usually focus on accurate execution within a defined workflow. Mid-level roles improve workflows and make decisions with moderate ambiguity. Senior roles design the system, remove recurring failure modes, and mentor others through judgment.
A senior analyst is not just a faster junior analyst. A senior detection engineer is not just someone who writes more rules. Seniority means more responsibility for the operating loop.
A practical progression looks like this:
- Execute the workflow accurately.
- Explain why the workflow exists.
- Improve the workflow when evidence shows it is failing.
- Design new workflows that other people can operate.
- Decide which work should be automated, delegated, or stopped.
What breaks when teams hire for tools instead of outcomes
Tool knowledge matters. No serious SOC can pretend otherwise. But hiring only for tool names creates brittle teams. Tools change, licensing changes, telemetry changes, and adversaries change. Outcome ownership is more durable.
Tool resumes create fragile coverage
A candidate who has used a SIEM is not automatically a detection engineer. A candidate who has used EDR is not automatically an incident responder. A candidate who has written Python is not automatically an automation engineer.
The useful question is what they did with the tool:
- Did they reduce noise without hiding real attacks?
- Did they add tests to detections?
- Did they improve enrichment quality?
- Did they shorten investigation time?
- Did they document failure modes?
If the answer is only that they clicked through a console, the coverage is fragile.
Alert queues hide architecture problems
Many teams try to hire more analysts when the queue grows. Sometimes that is necessary. Often it is a symptom of poor signal architecture.
More analysts will not fix duplicate alerts, missing asset context, broken identity enrichment, low-fidelity threat feeds, or detections that never get retired. Adding people to a broken queue can make the SOC look busier while making it less effective.
Practical rule: before hiring another person to work an alert queue, ask which alerts should not exist, which alerts should be enriched automatically, and which alerts should become detections with clearer ownership.
Automation without ownership becomes shelfware
Security automation fails when nobody owns the decision boundary. A playbook can enrich an IP address, disable a user, isolate a host, or open a ticket. But who decides when that action is safe? Who maintains the integration? Who handles partial failure? Who reviews false positives?
Automation is not a substitute for role clarity. It amplifies whatever workflow you already have. If the workflow is clean, automation helps. If the workflow is confused, automation spreads confusion faster.
Skills that compound across cybersecurity jobs
Some skills travel across almost every serious security operations role. They are not tied to a vendor. They make analysts better, engineers safer, responders calmer, and architects more realistic.
Telemetry literacy
Telemetry literacy means knowing where evidence comes from, what it can prove, and what it cannot prove. It includes endpoint events, DNS, proxy logs, authentication logs, cloud audit logs, email telemetry, network metadata, vulnerability data, and asset context.
The practical question is always evidence quality. Is the timestamp reliable? Is the user field normalized? Does the event represent an attempted action or a successful action? Is the log source complete? What blind spots exist?
Telemetry literacy prevents false confidence. It also prevents wasted investigation time.
Detection logic and hypothesis writing
Good detection starts as a hypothesis, not a query. For example: an attacker with stolen credentials may access a cloud console from an unusual geography and enumerate secrets before creating persistence. That hypothesis can become multiple detections, enrichment requirements, and test cases.
Weak detection starts with whatever fields are easiest to query. That produces rules that look useful but fail when attacker behavior changes.
A strong detection engineer can describe:
- The behavior being detected
- The data source required
- Expected false positives
- Known evasions
- Test data or replay method
- Owner and retirement criteria
Incident communication and evidence discipline
Cybersecurity jobs often fail at communication, not analysis. During an incident, people need clear statements about what is known, what is suspected, what is being done, and what decisions are needed.
Evidence discipline means keeping conclusions separate from observations. It means saying, the account authenticated from a new ASN and accessed three repositories, not, the user is compromised, unless the evidence supports that conclusion.
This matters because incident communication becomes business decision input. Legal, leadership, IT, customer support, and engineering may all act based on the responder's words.
Automation judgment
Automation judgment is the ability to decide what should be automated and what should remain human-reviewed. It includes idempotency, permissions, rate limits, rollback, audit logging, and exception handling.
Good automation candidates ask uncomfortable questions:
- What happens if enrichment times out?
- What happens if the same alert fires 300 times?
- Can the action be repeated safely?
- Is there a manual override?
- Who reviews the playbook after a false positive?
Those questions are not bureaucracy. They are production thinking.
A practical workflow for choosing your next cybersecurity job
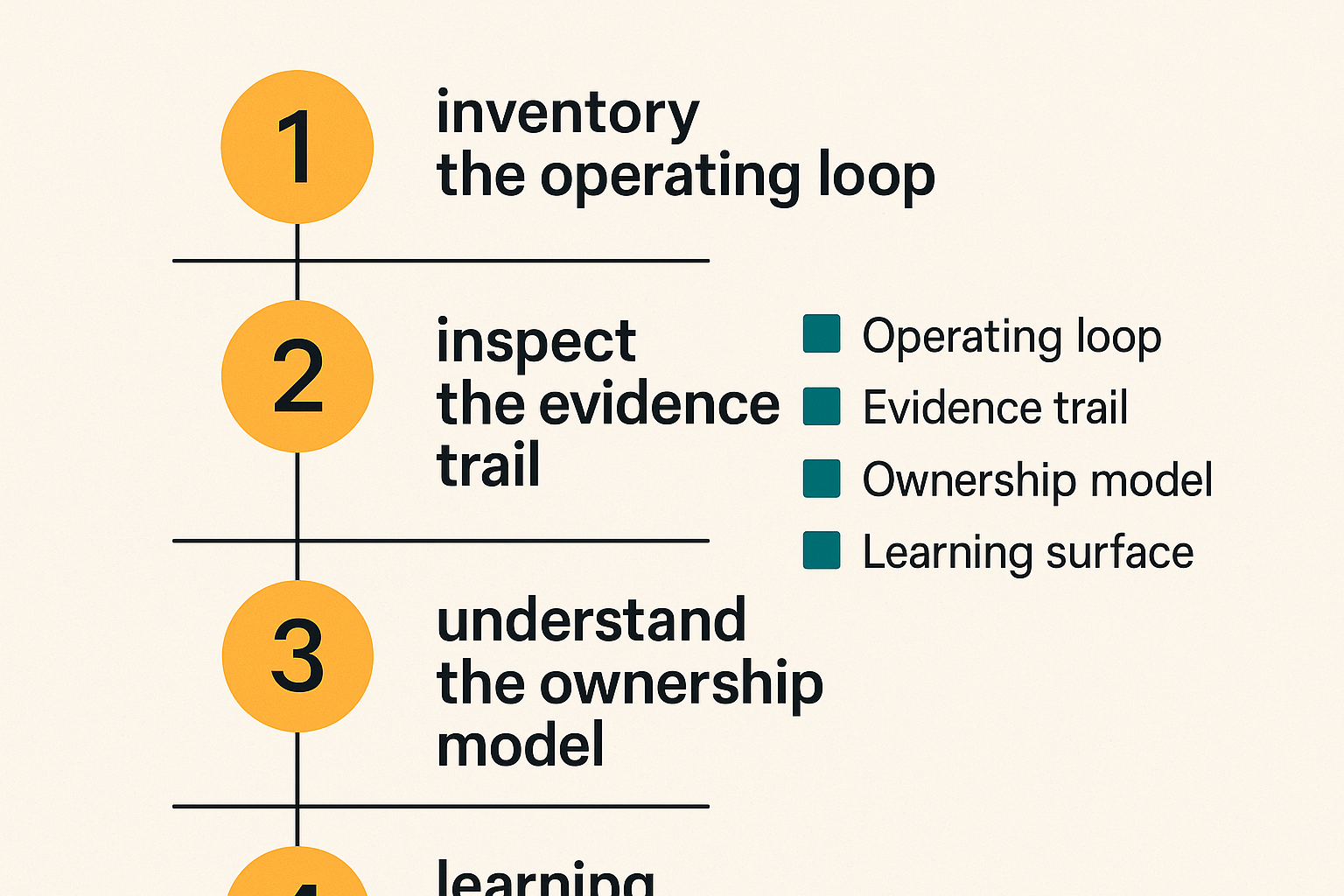
If you are evaluating cybersecurity jobs, do not only compare compensation, title, and remote policy. Those matter, but they do not tell you whether the role will make you better. Evaluate the operating environment.
Related reading from our network: even outside security, job quality increasingly depends on workflow leverage, which is why this adjacent guide to AI-assisted construction jobs is a useful reminder that tools only matter when they improve field execution.
Step 1 inventory the operating loop
Ask which loop the role owns. Is it triage, response, detection, automation, threat intelligence, exposure management, platform engineering, or architecture?
Then ask how success is measured. If the answer is vague, keep digging. Good answers sound like reduced mean time to investigate, improved detection coverage for priority techniques, higher quality escalations, fewer duplicate alerts, faster containment, or better post-incident remediation tracking.
Bad answers sound like more dashboards, more rules, more tickets, or more tools.
Step 2 inspect the evidence trail
Ask what artifacts the team uses every week:
- Alert records
- Case notes
- Timelines
- Detection pull requests
- Runbooks
- Post-incident reviews
- Threat intel briefs
- Automation logs
- Coverage maps
A team that cannot show artifacts probably runs on memory and heroics. That may be exciting for a month. It is not a great learning environment long term.
Step 3 test the ownership model
Ask who owns a detection after it fires. Ask who reviews false positives. Ask who updates the runbook after an incident. Ask who decides whether a threat intelligence source is worth keeping.
The goal is not to find a perfect team. Perfect teams do not exist. The goal is to find a team that knows where ownership is weak and is willing to fix it.
Practical rule: choose roles where your work leaves behind better systems, not just closed tickets.
Step 4 evaluate the learning surface
The best cybersecurity jobs expose you to real constraints. You want access to telemetry, feedback from incidents, engineers who understand systems, responders who explain decisions, and managers who protect time for improvement work.
Be cautious with roles that offer only queue work and no feedback loop. You can learn triage there, but the learning curve may flatten quickly. A role becomes more valuable when you can see how your decisions affect detection quality, response speed, and business risk.
Hiring cybersecurity jobs as a manager or architect
Hiring well starts before the job posting. It starts with defining the capability gap. Are you missing alert review capacity, detection engineering discipline, cloud response depth, automation maintenance, or architectural ownership?
If you cannot name the gap, you will hire a title and hope the person discovers the problem for you.
Write roles around decisions not products
A weak requirement says the candidate must know a specific tool. A stronger requirement says the candidate must be able to design, tune, test, and maintain detections using SIEM and endpoint telemetry. The product may still be listed, but the outcome is clear.
For example:
- Weak: Must know Splunk.
- Strong: Can build and maintain detection logic, validate event quality, manage false positives, and document coverage gaps in a SIEM environment.
- Weak: Must know SOAR.
- Strong: Can design safe enrichment and response workflows with logging, exception handling, approval gates, and rollback paths.
That changes the candidate pool. You stop filtering only for tool exposure and start filtering for operational judgment.
Interview with production artifacts
Do not interview only with trivia. Use realistic artifacts. Give the candidate a noisy alert. Give them a partial timeline. Give them a broken detection. Give them an automation playbook with a dangerous edge case.
Ask them to reason out loud:
- What do you know?
- What do you not know?
- What evidence would you collect next?
- What action would you avoid until you had more confidence?
- What would you change after the incident?
This reveals how the person thinks under ambiguity. It also reveals whether they can communicate clearly.
Build scorecards that reward judgment
A practical hiring scorecard should include:
- Evidence reasoning
- Workflow understanding
- Communication clarity
- Tool depth where required
- Automation safety
- Detection or response judgment
- Ownership mindset
- Ability to learn unfamiliar systems
Avoid scorecards that reward memorized acronyms more than operational reasoning. Knowledge matters, but production SOC work is full of incomplete information.
What works in production SOC teams
Some patterns keep showing up in teams that make cybersecurity jobs sustainable. They are not glamorous. They are operational.
Narrow ownership with explicit interfaces
Strong teams define narrow ownership without creating silos. A detection engineer may own rule quality, but the analyst owns escalation notes and the responder owns containment decisions. Interfaces connect the roles.
For example, a detection handoff might require:
- Detection name and owner
- Behavior hypothesis
- Required data sources
- Enrichment fields
- Triage instructions
- False-positive examples
- Test cases
- Expiration or review date
This turns detection into an operating asset, not a one-time query.
Runbooks that preserve context
Runbooks should not be scripts that tell people to click buttons without thinking. They should preserve the reasoning behind the workflow. The operator needs to understand why a step exists and when it should be skipped.
Good runbooks include decision points, required evidence, escalation paths, rollback guidance, and known failure cases. They also get updated after incidents. If a runbook is never changed, it is probably not connected to production learning.
For a deeper treatment of connected investigation steps, the ThreatCrush guide to threat analysis workflows breaks down how to reduce noise by linking signal, context, and response.
Metrics tied to response quality
Metrics shape behavior. If you measure only ticket closure speed, people will close tickets quickly. If you measure only alert volume, people will produce more alerts. If you measure only rule count, people will ship noisy detections.
Better SOC metrics connect to quality:
- Time to acknowledge credible alerts
- Time to collect required evidence
- Escalation accuracy
- False-positive rate by detection
- Detection coverage for priority behaviors
- Time from incident finding to detection improvement
- Containment decision latency
- Repeat incident patterns
The point is not to create a dashboard for its own sake. The point is to make the operating loop visible.
What fails in production SOC teams
What fails in practice is usually not effort. SOC teams work hard. The failure is often structural: unclear ownership, disconnected tools, and roles that do not map to the way work actually moves.
Generic analyst ladders
Generic ladders say analyst one, analyst two, analyst three, then senior analyst. That can work if each level has clear expectations. It fails when progression is just more alerts and harder shifts.
A better ladder maps growth to operating ownership. For example:
- Level one: accurate triage and evidence capture
- Level two: deeper investigation and escalation judgment
- Level three: detection feedback and incident coordination
- Senior: workflow improvement, mentoring, and cross-team ownership
This gives people a path that improves the SOC instead of burning them out.
Threat intelligence with no activation path
Threat intelligence is valuable only when it changes decisions. A feed that no one uses is not intelligence. A report that never maps to detections, hunts, exposure checks, or response priorities is just reading material.
Activation paths include:
- Add or tune detections
- Prioritize exposed assets
- Enrich active investigations
- Start a hunt hypothesis
- Update blocking or monitoring rules
- Brief incident commanders on actor behavior
Related reading from our network: local and sector teams face the same activation problem, and this model for threat intelligence asks and offers is a good way to think about exchange without turning intelligence into chat noise.
Career paths disconnected from architecture
Career growth fails when the architecture does not allow people to improve the system. If analysts cannot influence detections, responders cannot feed lessons back into controls, and engineers never see incident outcomes, everyone is trapped in partial information.
Good career paths give people increasing access to the full loop. They let analysts propose detection changes. They let responders drive post-incident improvements. They let engineers see operational pain. They let architects validate assumptions against real cases.
How AI and automation change cybersecurity jobs

AI is changing cybersecurity jobs, but not in the simplistic way the hype cycle suggests. It can summarize, enrich, classify, draft, correlate, and accelerate repetitive work. It does not remove the need for ownership.
The practical question is which parts of the workflow become cheaper and which decisions become more important.
AI compresses repetitive steps not accountability
AI can help with first-pass alert summaries, query generation, log explanation, case note drafting, phishing classification, and malware report summarization. That is useful. It can reduce friction in the middle of an investigation.
But accountability remains with the operator. If an AI summary misses an important authentication event, the responder still owns the decision. If generated detection logic creates blind spots, the detection engineer owns validation. If an automated response disables the wrong account, the organization owns the impact.
Treat AI output as a junior analyst with speed, not as a source of truth.
The new premium is validation
As automation produces more content, validation becomes more valuable. The scarce skill is not generating a query. The scarce skill is knowing whether the query detects the intended behavior, whether the data supports it, and whether the operational cost is acceptable.
Validation includes:
- Testing detections against known scenarios
- Comparing AI summaries to raw evidence
- Reviewing automation decisions
- Tracking false positives and false negatives
- Maintaining ground truth datasets
- Documenting assumptions
This creates new pressure on cybersecurity jobs. Operators who can validate systems will become more valuable than operators who only operate systems.
Humans still own risk decisions
Security work is full of business context. Is this host critical? Is this user a contractor, an executive, or a service account? Is downtime acceptable? Does legal need to be involved? Is this activity malicious, sanctioned, or unknown?
AI can help organize context, but humans still own risk decisions. The best teams will use AI to reduce mechanical work so humans spend more time on judgment, validation, and architecture.
Practical rule: automate collection and summarization aggressively, but keep containment, suppression, and risk acceptance behind explicit ownership until the workflow has proven itself.
Where ThreatCrush fits
Cybersecurity jobs become easier to define when the SOC has a clearer signal architecture. If threat intelligence, vulnerability context, attack surface data, and detection workflows live in disconnected places, every role spends too much time stitching context together.
ThreatCrush is built for operators who need fewer disconnected tools and more usable threat context inside real workflows.
Product fit for operators building SOC capability
ThreatCrush is not a replacement for role clarity. No platform is. But it can support the operating model this article describes by helping teams connect real-time threat feeds, vulnerability tracking, attack surface monitoring, and actor intelligence into the workflows analysts and engineers already run.
That matters for several cybersecurity jobs:
- SOC analysts get better context during triage.
- Detection engineers can map intelligence to coverage gaps.
- Incident responders can enrich investigations with actor and exposure context.
- Security architects can reduce tool fragmentation.
- Threat intelligence analysts can focus on activation instead of collection.
The goal is not more data. The goal is better decisions with less manual stitching.
When ThreatCrush is a good fit
ThreatCrush is a good fit when your team is trying to connect proactive and reactive security work. For example, when active exploitation intelligence should influence detection priority, when exposed assets should affect triage severity, or when actor context should help responders scope an incident faster.
It is less useful if the team has not decided who owns triage, detection, response, or intelligence activation. Tooling helps most when the workflow has a named owner.
The closing point is simple: cybersecurity jobs in 2026 are not just jobs. They are ownership positions inside a signal-to-decision system. Build your career or your team around that system, and the titles start making more sense.
Try threatcrush.com
You are writing for security operations professionals building and scaling SOC capabilities. Try threatcrush.com.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →