AI publishing threat detection as a SOC workflow, not a content policy

A publishing team ships hundreds of AI-assisted pages, emails, knowledge base updates, and social posts every week. The SOC gets pulled in only after a customer reports a malicious link, a brand impersonation page, or a strange article that should never have gone live.
That is where ai publishing threat detection stops being a content governance topic and becomes a security operations problem.
Teams think the problem is whether AI wrote the content. The real problem is whether the publishing workflow can detect compromised accounts, prompt injection, poisoned source material, unauthorized approvals, malicious outbound links, and policy bypass before they become incidents.
That changes the conversation. You are not buying an AI detector and calling it done. You are building telemetry, controls, alert logic, ownership, and response paths around a production content system that now moves faster than manual review can handle.
Table of contents
- Why AI publishing is now a detection surface
- The ai publishing threat detection model
- Signals that matter in AI content pipelines
- Workflow architecture from draft to response
- Detection engineering patterns for AI publishing systems
- Common failure modes and what breaks
- Investigation workflow for suspicious AI publishing
- Metrics that keep the program honest
- What works and what fails in production
- Where ThreatCrush fits into ai publishing threat detection
Why AI publishing is now a detection surface
The content pipeline is part of the attack surface
AI publishing changes the speed and shape of content operations. A single operator can draft, rewrite, translate, summarize, and schedule more material than an old review process was designed to handle. That is useful for the business. It is also useful for attackers.
The publishing surface now includes CMS accounts, AI writing tools, browser extensions, prompt libraries, shared documents, SEO automation, media generation, translation workflows, link insertion tools, API keys, scheduling systems, and approval queues. Some of these systems have enterprise controls. Many do not. Some produce audit logs. Many produce partial logs that are hard to correlate.
The mistake teams make is treating published content as a static artifact. In practice, the risky object is the chain of actions that created and approved it.
A bad article may be the visible symptom. The incident may be a compromised editor account, malicious prompt template, poisoned source document, hijacked integration token, or bulk publishing job that bypassed review.
The SOC cannot rely on editorial review alone
Editorial review catches grammar, tone, legal issues, and obvious brand problems. It is not built to detect lateral movement, anomalous authentication, API abuse, impossible travel, malicious link infrastructure, or sudden privilege escalation in a CMS.
Security review catches those patterns, but only if the SOC has the signals. Many teams do not send publishing telemetry to the SIEM. They monitor endpoint, cloud, identity, and network events, while the content stack operates as a separate business system.
That gap matters because attackers do not care whether the asset is called content. If a page on your domain can host a phishing link, serve malicious downloads, manipulate customers, or poison search results, it belongs in the detection model.
The useful boundary is workflow risk
A useful way to think about it is simple: AI is not the boundary. Workflow risk is the boundary.
If AI-assisted content can reach production, influence users, change public pages, modify documentation, publish support guidance, or trigger outbound campaigns, then it needs monitoring. If it is just a private drafting assistant with no path to publication, the risk is lower.
Practical rule: Do not start with the question, did AI write this. Start with, what path allowed this content to reach a trusted channel.
That distinction keeps the SOC focused. The goal is not to litigate authorship. The goal is to detect suspicious publishing behavior before it becomes brand abuse, fraud, malware delivery, or customer harm.
The ai publishing threat detection model
Detect behavior, not authorship
Most AI content detectors are weak security controls. They can be useful as editorial signals, but they are not reliable enough to serve as incident triggers. They also miss the real attack paths. A human can publish malicious content. An AI workflow can publish safe content. Authorship is not the same as threat.
AI publishing threat detection should focus on behavior:
- Who initiated the draft, edit, approval, or publication
- Which system generated or transformed the content
- Which data sources were used
- Which links, scripts, files, or embeds were added
- Whether approval matched policy
- Whether the action matched normal behavior for that user and asset
- Whether external infrastructure associated with the content looks risky
The practical question is not whether the sentence looks synthetic. It is whether the event sequence looks trustworthy.
Map the assets that can publish
Before writing rules, inventory the systems that can push content to public or customer-facing channels. For many organizations, this list is larger than expected.
Common publishing assets include:
- CMS platforms and headless CMS APIs
- Blog and documentation platforms
- Marketing automation systems
- Email campaign tools
- Social scheduling platforms
- Customer support knowledge bases
- Product update systems
- App store listings and release note workflows
- Translation management platforms
- AI writing and rewriting tools
- Automation platforms that connect drafts to publishing queues
The team at bl0ggers.com sees this from the creator side: when AI increases content throughput, the control plane has to move from manual eyeballing to structured approvals, logs, and reviewable state transitions.
For the SOC, that means every publishing path needs an owner, a logging source, and a clear answer to one question: what event tells us this asset changed trust state.
Tie content events to identity and approval
Identity is the hinge. A suspicious page is easier to investigate when the event includes user, role, device, IP, session, approval status, source tool, and change diff. Without that context, analysts are stuck comparing published pages manually.
At minimum, content events should preserve:
| Event field | Why it matters | Example use |
|---|---|---|
| actor id | Maps action to user or service account | Detect unexpected publisher |
| actor role | Shows whether action matched privilege | Editor publishing admin-only page |
| source system | Identifies tool or integration | AI assistant to CMS webhook |
| object id | Tracks page, campaign, or document | Cluster repeated edits |
| change type | Separates draft, approval, publish, delete | Alert only on high risk transitions |
| external links | Enables reputation enrichment | Newly added suspicious domain |
| approval state | Confirms policy path | Publish without required reviewer |
| timestamp | Supports sequence analysis | Bulk publish outside normal window |
This table is not glamorous. It is the difference between a useful alert and a Slack message that says something looks weird.
Signals that matter in AI content pipelines
Identity signals
Identity signals are usually the strongest starting point because publishing abuse often begins with account compromise or token misuse. Watch for:
- First-time publication from a user
- Publication from a new device or country
- Impossible travel near a content event
- Service account publishing outside expected automation windows
- Role changes followed by immediate publication
- Failed MFA followed by successful publish action
- API token created shortly before a bulk update
- Dormant account reactivated and used for content edits
These are familiar SOC patterns. The difference is the target system. A CMS event should not be lower priority than a SaaS admin event if the CMS controls trusted public pages.
Practical rule: Treat publish permission like production deploy permission. If it can change what customers trust, monitor it like a production control.
Content and link signals
Content signals are useful when they are concrete. Avoid vague alerts like suspicious tone or likely AI. Prioritize indicators that map to harm.
Useful content and link signals include:
- Newly added domains with no prior relationship to the brand
- URL shorteners in documentation, support pages, or transactional emails
- Download links added by users who rarely edit that page type
- Embedded scripts or iframes in content fields that normally contain text
- Crypto wallet addresses, payment instructions, or bank details added to pages
- Login language pointing users to non-owned domains
- Sudden changes to security, billing, refund, or support instructions
- Hidden text, cloaked links, or unusual HTML attributes
- Prompt artifacts that reveal internal instructions or source material
The best content detections are not trying to judge prose quality. They are looking for risky objects inserted into trusted channels.
Workflow and timing signals
Workflow anomalies catch bypass and automation abuse. These signals are especially important when AI tools generate many drafts quickly.
Examples:
- Draft created, approved, and published by the same actor when policy requires separation
- Bulk publish job that skips staging
- Approval after publication instead of before publication
- Content modified after final review but before go-live
- Publication outside normal business hours for that team
- High volume of edits across unrelated page categories
- Translation workflow overwriting source content
- Scheduled campaign changed minutes before send
What breaks in practice is not usually one strange sentence. It is an unexpected state transition.
Workflow architecture from draft to response
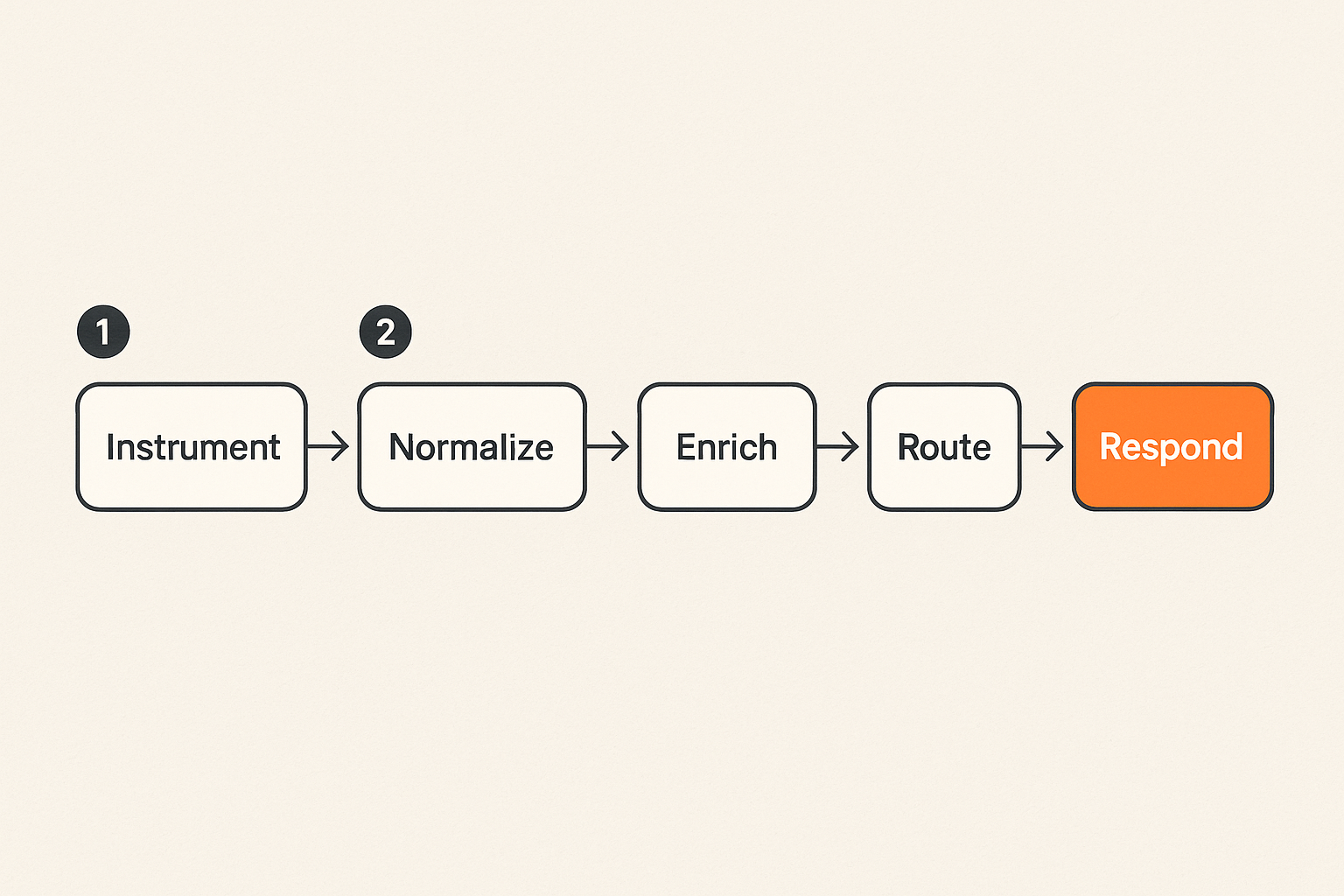
Step one instrument the pipeline
Start by instrumenting the systems that already know what happened. Do not ask analysts to scrape pages or manually inspect content history unless there is no alternative.
Sources to connect:
- CMS audit logs
- Identity provider logs
- AI tool audit logs where available
- Webhook events for draft, approve, publish, unpublish, delete
- Git or content repository history
- Link scanning and domain reputation services
- Endpoint and browser telemetry for users with publish access
- Ticketing or approval systems
If the publishing platform supports webhooks, emit events on every trust transition. A simple event envelope is enough at first:
event_type: content.publish
object_type: knowledge_base_article
object_id: kb-1842
actor_id: user-771
actor_role: editor
source_system: ai_draft_tool
approval_state: approved
external_links:
- hxxps://example-download-site.invalid/file
risk_flags:
- new_external_domain
- after_hours_publish
The schema will evolve. The important thing is to preserve identity, object, action, and risk context.
Step two normalize events
Publishing tools describe the same action differently. One platform says publish. Another says release. Another says send. Another says sync. Normalize these into a small event model:
- draft created
- content changed
- approval requested
- approval granted
- content published
- content unpublished
- content deleted
- permissions changed
- integration token created
- scheduled send changed
Normalization lets detection engineers write rules once and apply them across channels. It also helps incident responders reconstruct timelines quickly.
A useful normalized event should answer:
- What changed
- Who changed it
- Where it changed
- How it reached production
- Whether that path matched policy
Step three route decisions
Not every event needs a SOC alert. Most publishing events are normal business operations. The routing layer should separate audit, review, and incident paths.
| Route | When to use it | Owner | Example |
|---|---|---|---|
| Audit only | Normal low risk activity | Content ops | Approved blog update |
| Editorial review | Policy or brand concern | Editorial lead | AI disclosure missing |
| Security review | Suspicious but not urgent | Security analyst | New external domain in support article |
| Incident response | High consequence or active abuse | IR lead | Compromised account publishes phishing link |
This is where security teams reduce noise. The SOC should not become a copy desk. It should receive events where security context changes the decision.
Practical rule: Alert the SOC on dangerous combinations, not isolated content facts.
Detection engineering patterns for AI publishing systems
Baseline normal publishing behavior
Good detection starts with normal. For each publishing channel, define expected behavior:
- Which roles can publish
- Which users publish frequently
- Which pages or categories are high consequence
- Which hours are normal
- Which source systems are approved
- Which external domains are common
- Which approval paths are required
- Which actions are automated
A baseline does not need to be perfect. It needs to be good enough to identify events that deserve enrichment.
Example rule logic:
rule: publish_from_new_actor_on_high_trust_page
when:
event_type: content.publish
object_category:
- billing
- login
- security
- support
conditions:
actor_has_published_category_before: false
approval_state: approved
severity: medium
actions:
- enrich_actor_identity
- scan_external_links
- notify_content_owner
This avoids broad alerting on every first-time publisher. It focuses on high-trust pages where user harm is plausible.
Write rules for high consequence changes
Some content changes are inherently more sensitive than others. Detection should prioritize changes that affect trust, money, authentication, software downloads, or support paths.
High consequence changes include:
- Login URLs
- Password reset instructions
- Billing instructions
- Refund procedures
- Download links
- API keys or code snippets
- Security advisories
- Incident status pages
- Compliance documentation
- Customer support escalation paths
For these assets, require stronger controls: separation of duties, link reputation checks, diff review, and post-publication monitoring.
The mistake teams make is applying the same review policy to every page. A typo fix in a culture blog post and a new link on a password reset article do not deserve the same security treatment.
Use enrichment before escalation
Raw events are noisy. Enrichment turns them into decisions.
Useful enrichment steps:
- Check whether the external domain is brand-owned or previously approved
- Compare actor behavior to historical patterns
- Pull recent identity alerts for the actor
- Look for recent role or permission changes
- Scan links for redirects, downloads, and suspicious certificates
- Check whether the content object is high consequence
- Compare the diff against sensitive terms or objects
- Identify whether the event came from a known automation account
A content.publish event with one new link is not automatically an incident. A content.publish event with a new download domain, from a new device, by a recently elevated user, on a high-trust page is a different story.
That changes the conversation from alert volume to alert quality.
Common failure modes and what breaks
False confidence from AI content detectors
The most common failure mode is buying an AI detector and treating the score as a security signal. These tools can be wrong, inconsistent, and easy to misinterpret. Even when they are right, the result often does not matter to the SOC.
An AI-written article can be harmless. A human-written article can contain a credential harvesting link. A copied support article can be modified by a compromised account. A translated page can overwrite safe instructions with malicious ones.
What breaks in practice is trust in the alert stream. Analysts get low-value flags. Editorial teams get frustrated. Security stops looking at content events. Attackers keep using the workflow.
AI authorship detection may belong in editorial governance. It should not be the center of ai publishing threat detection.
Disconnected tools and missing ownership
Another failure mode is disconnected tooling. The CMS has logs. The AI tool has activity history. The identity provider has authentication events. The link scanner has findings. The approval system has tickets. Nobody owns the join.
When an incident happens, the investigation becomes a meeting instead of a workflow.
Typical symptoms:
- SOC cannot tell who approved a page
- Content ops cannot tell whether a login was suspicious
- Legal cannot tell how many customers saw the page
- Engineering cannot roll back quickly
- Leadership cannot tell whether the issue is contained
Ownership should be explicit. Content ops owns policy and review. Security owns detection and response. Platform owners own logging and access controls. Incident response owns containment coordination when customer harm is possible.
No rollback path
Detection without rollback is theater. If a malicious page goes live, the team needs a fast way to unpublish, revert, invalidate caches, cancel campaigns, and preserve evidence.
Rollback should cover:
- CMS version restore
- Unpublish or quarantine state
- CDN cache purge
- Email campaign pause
- Social post removal where possible
- Search indexing controls where relevant
- Credential and token rotation
- Account disablement
- Evidence export
The rollback path should be tested before the incident. If only one marketing admin knows how to revert a critical page, the SOC does not have an operational control. It has a dependency.
Investigation workflow for suspicious AI publishing
Triage the event cluster
A single event rarely tells the whole story. Start by clustering related activity around the content object, actor, source system, and external indicators.
Ask:
- What changed in the content diff
- Who initiated the change
- Was the actor authenticated normally
- Was the actor recently granted new permissions
- Which tool or integration performed the action
- Were external links or files added
- Did the content bypass approval
- Were related pages modified
- Was the content viewed, emailed, or indexed
The first analyst action should be context assembly, not page reading. Page reading matters, but it comes after the timeline is clear.
Validate user intent
User validation is often faster than deep forensic analysis. If the actor is a legitimate employee, confirm whether the action was expected. Do this through a trusted channel, not by replying to a potentially compromised session.
Validation outcomes:
- Expected action, low risk, close or downgrade
- Expected action, policy issue, route to editorial or content ops
- Unexpected action, possible compromise, escalate
- Actor unreachable, high consequence content, contain first
Be careful with service accounts. A service account cannot confirm intent. For automation, validate against deployment records, scheduled jobs, and approved workflow changes.
Contain content and credentials
Containment has two tracks: content containment and identity containment.
Content containment:
- Unpublish or quarantine the affected object
- Revert to the last known good version
- Remove or block malicious links
- Purge caches if the page was public
- Pause campaigns that distributed the content
- Preserve the malicious version for evidence
Identity containment:
- Disable or restrict the actor account if compromise is suspected
- Revoke active sessions
- Rotate API tokens and integration secrets
- Review recent permission changes
- Hunt for related activity in adjacent systems
The practical question is how quickly the team can reduce user exposure while preserving enough evidence to understand root cause.
Metrics that keep the program honest
Measure review load
Security programs fail when they create review queues nobody can operate. Track review load early.
Useful metrics:
- Number of publishing events per week
- Percentage routed to audit, editorial review, security review, and incident response
- Median time to review high consequence changes
- Number of alerts per publishing channel
- Number of alerts per rule
- Percentage of alerts closed as expected business activity
These metrics show whether the detection model is tuned to workflow reality. If 40 percent of all content events require manual security review, the model is broken. If high consequence changes never generate review, the model is also broken.
Measure detection quality
Detection quality is not just false positives. It is whether the alert carried enough context for the analyst to make a decision.
Track:
- Alerts with complete actor, object, source, and approval context
- Alerts requiring manual log gathering
- Alerts with link reputation enrichment
- Alerts correlated with identity risk
- True positive security incidents
- Policy violations routed outside the SOC
- Rules disabled because of noise
A noisy rule may still be useful if enrichment improves it. A clean rule may still be weak if it catches only obvious events after harm has occurred.
Measure response readiness
Response readiness tells you whether detection can become action.
Track:
- Time to unpublish high risk content
- Time to revoke compromised publishing access
- Time to identify all affected objects
- Time to notify content owner
- Number of channels with tested rollback
- Number of high consequence assets without owner mapping
This is where ai publishing threat detection becomes operational. The team is not just finding suspicious pages. It is reducing exposure time.
What works and what fails in production
What works
What works is boring and durable:
- Inventory publishing systems and paths to production
- Normalize content events into a common schema
- Correlate content activity with identity and approval data
- Prioritize high consequence assets
- Enrich links and external objects before alerting
- Route editorial issues away from the SOC
- Test rollback and containment paths
- Review detections with content owners monthly
This approach is not flashy. It is how teams turn AI-assisted publishing into a monitored business workflow.
What fails
What fails is usually control theater:
- Blocking all AI tools while teams use shadow workflows
- Treating AI detector scores as security truth
- Sending every content anomaly to the SOC
- Ignoring service accounts and integration tokens
- Monitoring only public pages, not workflow transitions
- Requiring manual review without preserving logs
- Building alerts with no owner or response path
- Assuming editorial approval equals security validation
The skeptical view is the right one here. If a control does not change detection, decision quality, or response speed, it probably will not survive production pressure.
A practical implementation sequence
For a team starting from limited visibility, use a phased sequence:
- Pick one high consequence channel. Start with support docs, billing pages, login guidance, release notes, or customer emails. Do not boil the ocean.
- Inventory publishing paths. Identify users, service accounts, AI tools, automation, approval systems, and APIs that can publish.
- Emit normalized events. Capture draft, edit, approve, publish, unpublish, permission change, and token creation events.
- Correlate identity context. Join content events with SSO, MFA, device, role, and recent permission activity.
- Add link and object enrichment. Flag new domains, redirects, downloads, scripts, embeds, wallet addresses, and payment instructions.
- Write three high value detections. Focus on publish without approval, high consequence page with new external link, and publish by anomalous actor.
- Define routing. Decide what goes to content ops, security review, and incident response.
- Test rollback. Run a tabletop where a malicious support article goes live and must be removed, cached copies purged, and credentials rotated.
- Review results. Tune rules based on alert quality, not internal politics.
- Expand channel by channel. Add the next publishing surface only after the first one has stable telemetry and ownership.
Practical rule: Build the first version around one critical workflow and one real response path. Coverage without action is just inventory.
Where ThreatCrush fits into ai publishing threat detection
Connect proactive and reactive signals
AI publishing threat detection sits between proactive risk management and reactive incident response. The SOC needs to know which publishing assets matter before an alert fires, but it also needs fast correlation when something suspicious happens.
That means connecting:
- Asset criticality
- Identity risk
- Content workflow events
- Threat intelligence on links and domains
- Detection logic
- Investigation notes
- Response actions
Threat detection platforms are most useful when they reduce the number of places an analyst has to look. For publishing abuse, that means turning a content event into an investigation with actor context, object context, external indicator context, and recommended containment steps.
Give every alert an owner and next step
The right product fit is not another generic AI badge. It is a workflow that helps the SOC decide what to do next.
A useful alert should say:
- What changed
- Why it matters
- Who owns the asset
- Whether the actor looks risky
- Whether the content includes risky external objects
- Which policy was bypassed
- What containment action is available
That is the operational center of ai publishing threat detection. The topic sounds new because AI is involved. The SOC pattern is familiar: collect signals, normalize events, enrich context, route decisions, validate response, and tune based on what happens in production.
Try threatcrush.com
ThreatCrush helps security teams connect signals, workflows, detection, and response so alerts become decisions instead of noise. Try threatcrush.com for a practical way to operationalize ai publishing threat detection across your SOC.
Try ThreatCrush
Real-time threat intelligence, CTEM, and exposure management — built for security teams that move fast.
Get started →